

機械学習に数学の知識は必要?最低限の基礎知識を徹底解説
ここでは、機械学習(Machine Learning)や深層学習(Deep Learning)を理解するうえで必要な数学の知識について解説します。求められる数学の最低限の基礎知識としては、「微分」「線形代数」「確率・統計」の3分野があります。本稿ですべてをカバーすることはできませんが、重要な項目を中心にピックアップしますので、ぜひ押さえておきましょう。
機械学習の基礎については以下の記事で詳しく解説しているため、あわせてご覧ください。
エンジニアとしての市場価値を知るために
年収査定を受ける(無料)なぜ機械学習において数学の知識が必要なのか?
機械学習とは、簡単にいうとコンピュータによって、データに含まれるルールやパターンを検出するモデル(関数)を導き出し、そのモデルを使って未知のデータから、新たな予測や分類を行う手法です。例えば、画像や音声の認識、迷惑メールの分類、ECサイトの商品レコメンドなど、多様な分野で利用されています。
理想的なモデルをつくるには、複数のパラメータを導き出すことが重要になります。機械学習(教師あり)編で触れましたが、例えば単回帰分析では、ある一次関数
\( y=a x+b \)
![]() が多くのデータにフィットするように(各データの残差の合計が最も小さくなるように)、「最小二乗法」を使って最適な傾き
\(a\)
が多くのデータにフィットするように(各データの残差の合計が最も小さくなるように)、「最小二乗法」を使って最適な傾き
\(a\)
![]() と切片
\(b\)
と切片
\(b\)
![]() を求めます。
を求めます。
ここで「目的関数」と呼ばれる関数(モデル)の値を最小化(あるいは最大化)することで、最適なパラメータを決定しますが、最小二乗法ではモデルが適切な場合には出力値が小さくなります。そこで、この目的関数の最小化問題を解くために、簡単な微分や線形代数、さらにデータを加工するための統計の知識が必要になるわけです。
エンジニアとしての市場価値を知るために
年収査定を受ける(無料)微分の基礎知識
そもそも微分とは? その定義を復習
まず微分とは何でしょう? 厳密性を無視して簡単にいうと、微分とは「ある関数
\(y=f(x)\)
![]() 上の1点、例えば
\(x=a\)
上の1点、例えば
\(x=a\)
![]() における接線の傾きを求めること」を意味しています。この傾きは「平均変化率(変化の割合)」とも呼ばれます。
例えば、ある関数
\(y=f(x)\)
における接線の傾きを求めること」を意味しています。この傾きは「平均変化率(変化の割合)」とも呼ばれます。
例えば、ある関数
\(y=f(x)\)
![]() において、
\(x\)
において、
\(x\)
![]() が
\(a\)
が
\(a\)
![]() から
\(b\)
から
\(b\)
![]() まで変化するとき、平均変化は
\(\frac{f(b)-f(a)}{b-a}\)
まで変化するとき、平均変化は
\(\frac{f(b)-f(a)}{b-a}\)
![]() になります。
になります。
ここで
\(b\)
![]() の値を限りなく
\(a\)
の値を限りなく
\(a\)
![]() に近づけると、図のように点
\(Q\)
に近づけると、図のように点
\(Q\)
![]() における接線の傾きが求められます。
における接線の傾きが求められます。
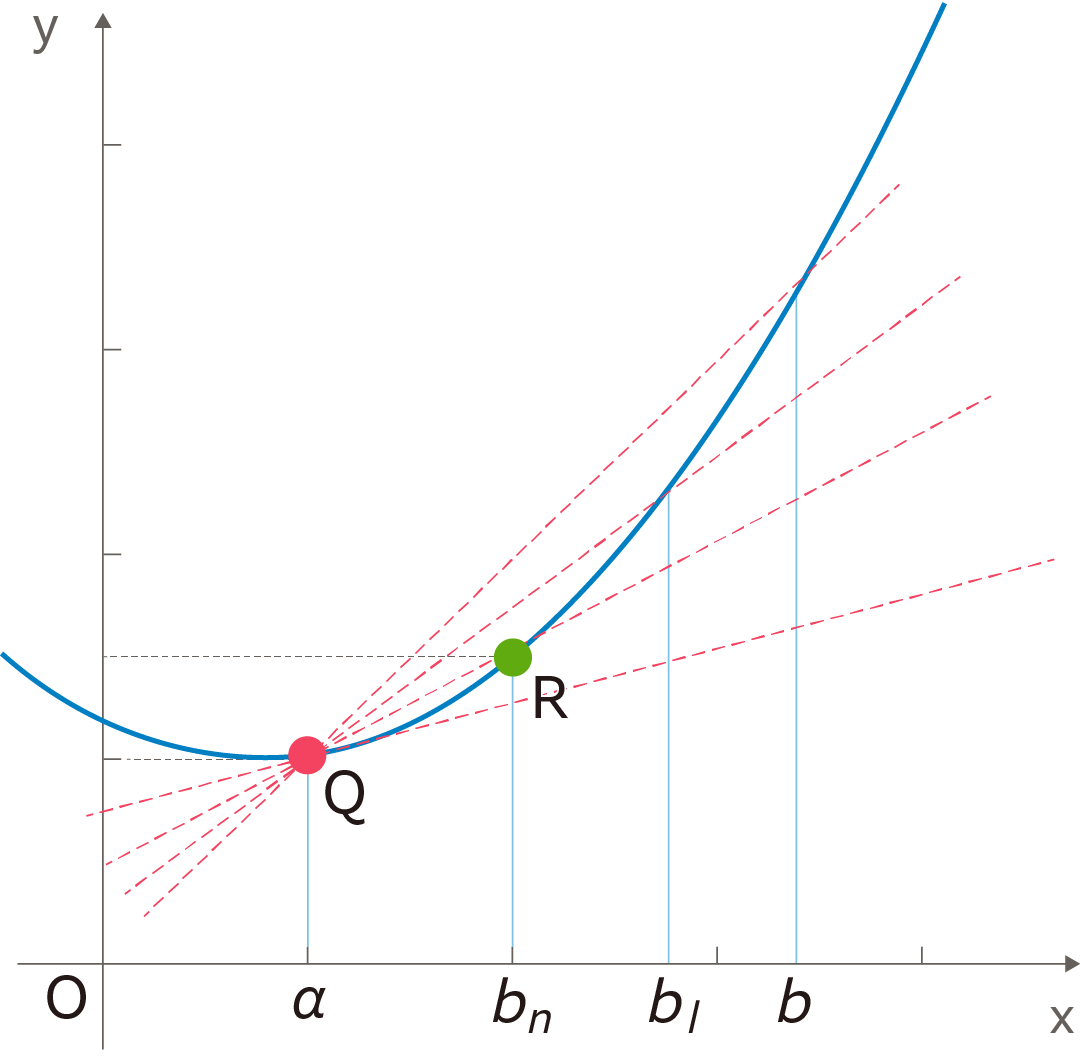
これを下図のように一般化して、ある関数
\(f(x)\)
![]() の
\(x=a\)
の
\(x=a\)
![]() における平均変化率(傾き)を求めることを、「微分係数を求める」といいます。
における平均変化率(傾き)を求めることを、「微分係数を求める」といいます。
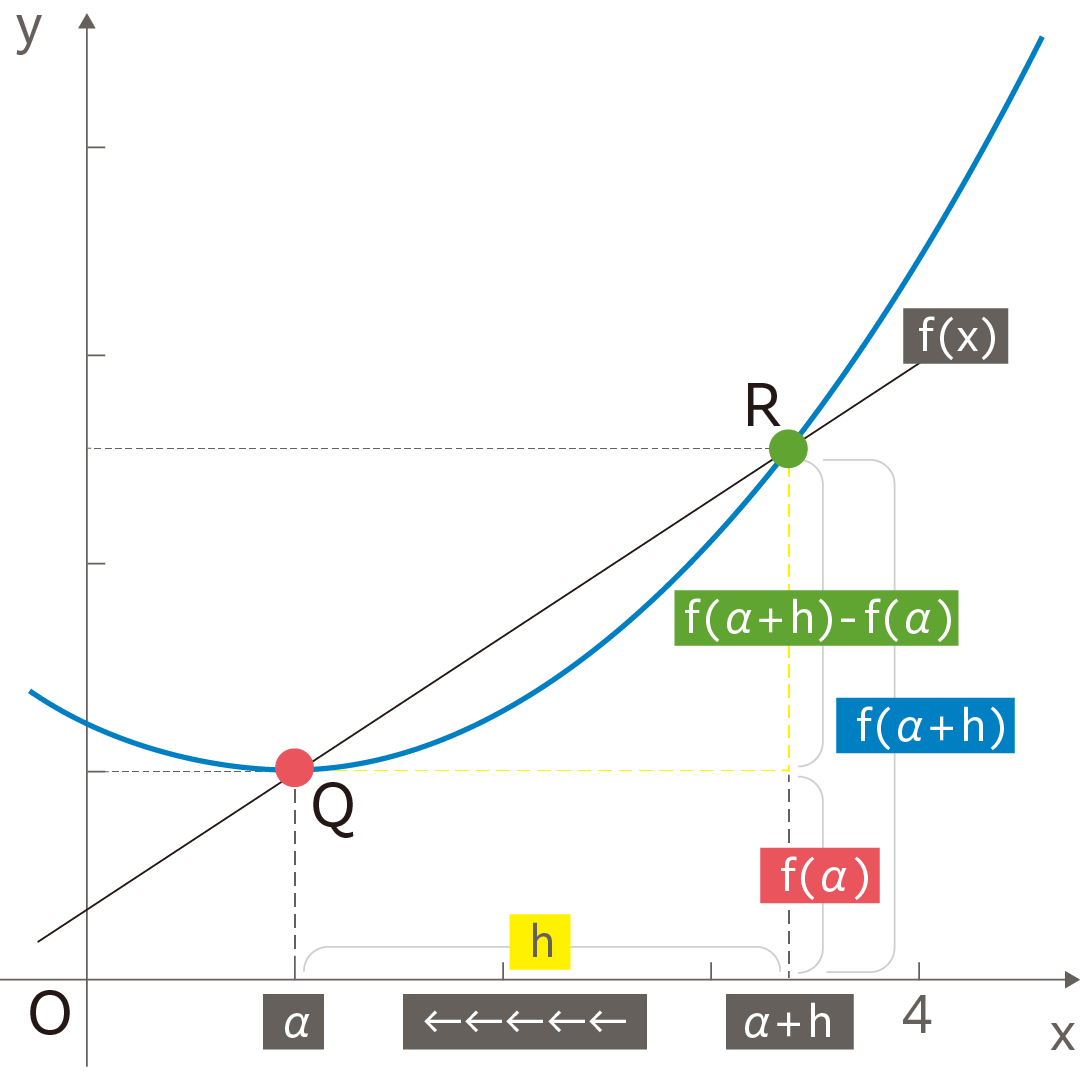
関数
\(f(x)\)
![]() のどの点でも微分係数を求められるように、
$$h=b-a$$
$$a=x$$
のどの点でも微分係数を求められるように、
$$h=b-a$$
$$a=x$$
![]()
と置き、新しい関数として、以下のように導関数
\(f' (x)\)
![]() を求めます。
を求めます。
$$f^{\prime}(x)=\lim _{h \rightarrow 0} \frac{f(x+h)-f(x)}{h}$$
![]()
これを微分するといいます。
\(\lim\)
![]() は「極限」を表す記号で、ここでは
\(h\)
は「極限」を表す記号で、ここでは
\(h\)
![]() を限りなくゼロに近づける操作になります。
を限りなくゼロに近づける操作になります。
導関数
\(f' (x)\)
![]() の別表現には、
\(\frac{d}{dx}f(x) \)
の別表現には、
\(\frac{d}{dx}f(x) \)
![]() 、
\(\frac{dy}{dx}\)
、
\(\frac{dy}{dx}\)
![]() などがあります。後ほど説明する偏微分では、多変数の関数を扱うため、変数を明確にするために記法として
\(\frac{dy}{dx}\)
などがあります。後ほど説明する偏微分では、多変数の関数を扱うため、変数を明確にするために記法として
\(\frac{dy}{dx}\)
![]() を使うことにします。
を使うことにします。
1変数関数の最小値の必要条件
導関数
\(f' (x)\)
![]() は、前述のように接線の傾きを表すため、次のように最適化で利用される基本原理が得られます。
は、前述のように接線の傾きを表すため、次のように最適化で利用される基本原理が得られます。
$$滑らかな関数 f(x) が x=a で最小値になるとき、f' (a)=0 $$
![]()
これは下図から明らかですが、あくまで必要条件であって、必要十分条件ではないことに注意しましょう。つまり関数
\(f(x)\)
![]() によっては極値が複数あり、
\((f' (α)=0)\)
によっては極値が複数あり、
\((f' (α)=0)\)
![]() が極大値になることもあるし、極小値であってもその点で最小値になるとは限らないからです。
が極大値になることもあるし、極小値であってもその点で最小値になるとは限らないからです。
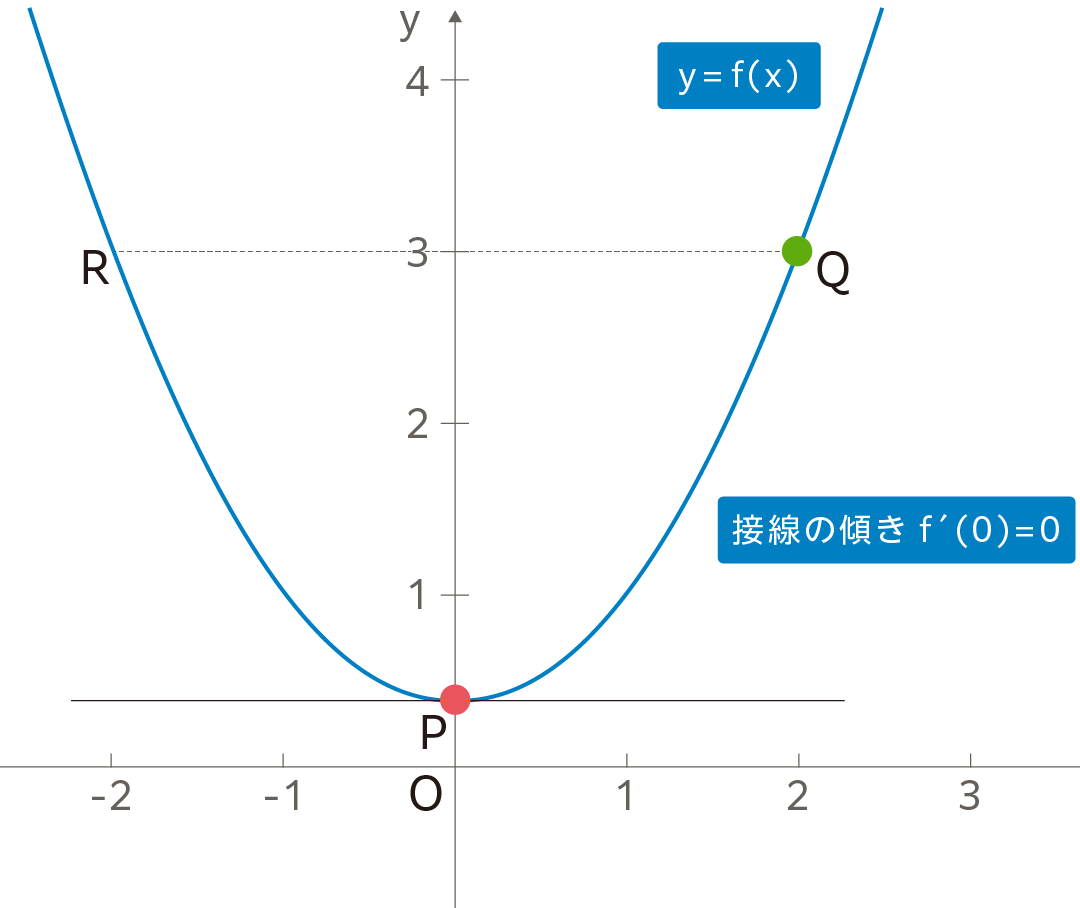
これだけは押さえたい微分の基本公式
さて、微分の意味が理解できたところで、以下に微分の計算で、これだけは押さえたい基本公式を挙げておきます。個々の証明は割愛しますが、最低限の公式として覚えておいてください。
\(c\) :定数、 \(x\) :変数として
【 \(c\) の微分】\((c)´=0\)
(定数は変化しないのでゼロ)
【 \(x\) の微分】\((x)´=1\) ( \(y=x\) は傾きが1)
【定数倍の微分】 \((cf(x))´=cf´(x)\)
【 \(n\) 乗の微分】 \(\left(x^n\right)^{\prime}=n x^{(n-1)}\)
【和・差の微分】 \((f(x)±g(x))´=f´(x)±g´(x)\)
【積の微分】 \((f(x)g(x))´=f´(x)g(x)+f(x)g´(x)\)
【合成関数の微分】 \(y'=(f(g(x)))´=f´(g(x))・g´(x)\)
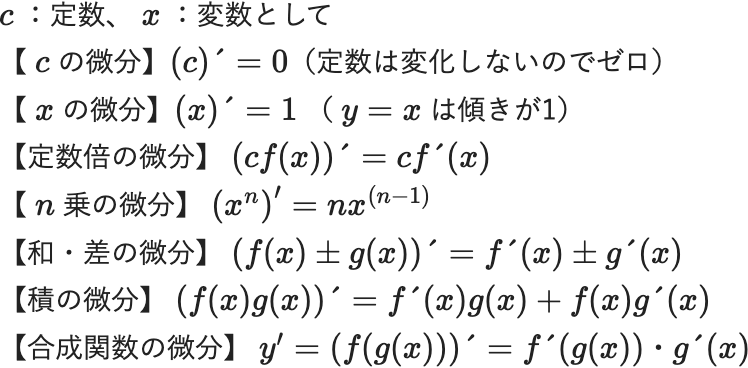
(合成関数とは、2つの関数があり、1つの関数の箱に、もう1つの関数を入れるイメージです。チェーンルールとして機械学習に多用されます)
複数の入力変数がある場合に登場する偏微分
ここまでは変数
\(x\)
![]() が 1つの話でしたが、 機械学習のシーンでは複数の入力変数、
\(x_1,x_2,…,x_i\)
が 1つの話でしたが、 機械学習のシーンでは複数の入力変数、
\(x_1,x_2,…,x_i\)
![]() を用いて、1つの出力を予測することが一般的です。そこで偏微分を使います。多変数の微分で、ある入力変数
\(x_i\)
を用いて、1つの出力を予測することが一般的です。そこで偏微分を使います。多変数の微分で、ある入力変数
\(x_i\)
![]() に着目し、それ以外の変数を「定数」とみなして微分します。偏微分は、以下の記号で表現します。
$$\frac{\partial}{\partial x_m} f\left(x_1, x_2, \ldots, x_i\right)$$
に着目し、それ以外の変数を「定数」とみなして微分します。偏微分は、以下の記号で表現します。
$$\frac{\partial}{\partial x_m} f\left(x_1, x_2, \ldots, x_i\right)$$
![]()
例えば、
\(f(x_1, x_2 )=4x_1^2+3x_2 \)
![]() のとき、
\(x_1\)
のとき、
\(x_1\)
![]() で偏微分すると
で偏微分すると
$$ \begin{eqnarray}\frac{\partial}{\partial x_1} f\left(x_1, x_2\right) &=&\frac{\partial}{\partial x_1}\left(4 x_1^2+3 x_2\right)\\ &=&\frac{\partial}{\partial x_1}\left(4 x_1^2\right)+\frac{\partial}{\partial x_1}\left(3 x_2\right)\\ &=&4 \frac{\partial}{\partial x_1}\left(x_1^2\right)+3 x_2 \times \frac{\partial}{\partial x_1}(1) \\ &=&4 \times 2 x_1+3 x_2 \times 0\\ &=&8 x_1 \end{eqnarray}$$
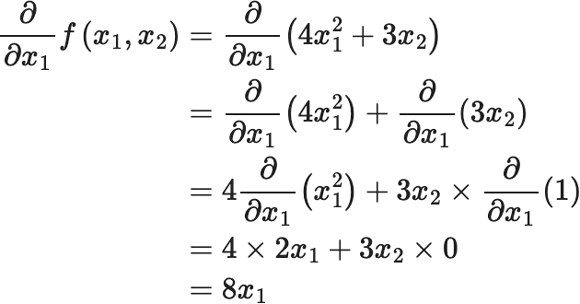
となります。
多変数関数の最小値の必要条件
先ほど滑らかな1変数関数 \(f(x)\)
![]() が
\(x=a\)
が
\(x=a\)
![]() で最小値になる必要条件は、導関数が0であると説明しましたが、多変数関数になっても同じ考え方が適用できます。例えば、2変数関数の場合には下記のようになります。
$$関数 z=f(x,y) が最小値になるとき、$$
$$\frac{\partial f}{\partial x}=0 \quad \frac{\partial f}{\partial y}=0 \:①$$
で最小値になる必要条件は、導関数が0であると説明しましたが、多変数関数になっても同じ考え方が適用できます。例えば、2変数関数の場合には下記のようになります。
$$関数 z=f(x,y) が最小値になるとき、$$
$$\frac{\partial f}{\partial x}=0 \quad \frac{\partial f}{\partial y}=0 \:①$$
関数 ![]() が最小値になるとき、
が最小値になるとき、
![]()
これはワイングラスを思い浮かべて、その立体を
\(X\)
![]() 軸方向、あるいは
\(Y\)
軸方向、あるいは
\(Y\)
![]() 軸方向に切って断面を見れば、それぞれ2次曲線になるため、傾きが両方ともゼロになる接平面の場所が最小値になると考えればよいでしょう(あくまで必要条件です)。こちらは例題を後述します。
軸方向に切って断面を見れば、それぞれ2次曲線になるため、傾きが両方ともゼロになる接平面の場所が最小値になると考えればよいでしょう(あくまで必要条件です)。こちらは例題を後述します。
エンジニアとしての市場価値を知るために
年収査定を受ける(無料)機械学習で微分を利用するシーンとは?
最小二乗法について
では、機械学習で微分を利用するシーンを少し見てみましょう。機械学習の教師あり学習編では、一例として最もシンプルな単回帰分析について解説しました。このとき「最小二乗法」により最適なモデル(関数)を導けると説明しました。
例えば
\(n\)
![]() 個のデータがあり、そのうちの
\(k\)
個のデータがあり、そのうちの
\(k\)
![]() 番目の要素の実測値
\(y_k\)
番目の要素の実測値
\(y_k\)
![]() において、あるモデルから算出される予測値
\(y ̅_k\)
において、あるモデルから算出される予測値
\(y ̅_k\)
![]() とするとき、単回帰方程式
\(y ̅_k=ax_k+b\)
とするとき、単回帰方程式
\(y ̅_k=ax_k+b\)
![]() を求めます。実測データがこの式からどのくらい離れているのか、それぞれの距離(差)を計算し、誤差として2乗 した「平方誤差」を求めます。実測値
\(y_k\)
を求めます。実測データがこの式からどのくらい離れているのか、それぞれの距離(差)を計算し、誤差として2乗 した「平方誤差」を求めます。実測値
\(y_k\)
![]() と予測値
\(y ̅_k\)
と予測値
\(y ̅_k\)
![]() の残差 (誤差)を
\(e_k = y_k - y ̅_k\)
の残差 (誤差)を
\(e_k = y_k - y ̅_k\)
![]() とすると、平方誤差とは 以下のようになります。
$$\mathrm{e}_k^2=\left(y_k-\bar{y}_k\right)\left(y_k-\bar{y}_k\right)$$
とすると、平方誤差とは 以下のようになります。
$$\mathrm{e}_k^2=\left(y_k-\bar{y}_k\right)\left(y_k-\bar{y}_k\right)$$
![]()
これらが実測データごとに
\(n\)
![]() 個あるので、次のように総和
\(E\)
個あるので、次のように総和
\(E\)
![]() を取って誤差を最小にします。
$$E=\left(y_1-\bar{y}_1\right)^2+\left(y_1-\bar{y}_1\right)^2+\cdots\left(y_n-\bar{y}_n\right)^2$$
を取って誤差を最小にします。
$$E=\left(y_1-\bar{y}_1\right)^2+\left(y_1-\bar{y}_1\right)^2+\cdots\left(y_n-\bar{y}_n\right)^2$$
![]()
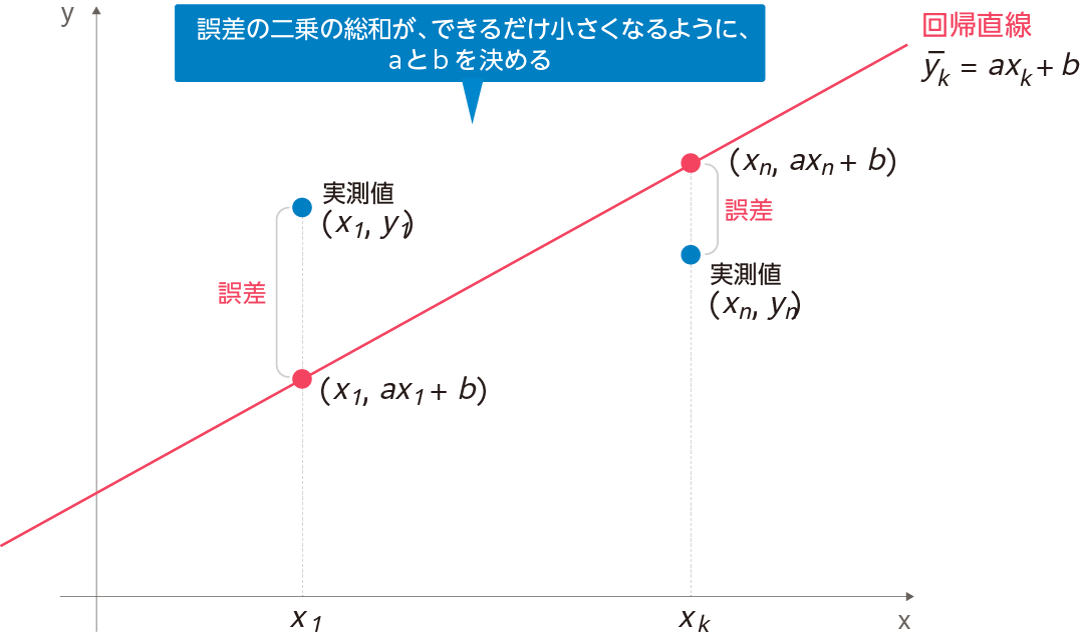
ここで誤差の総和
\(E\)
![]() の式は、最適化のための目的関数と呼びます。この目的関数が最小になれば、予測値をはじき出す最適なモデルとしてのパラメータ
\(a\)
の式は、最適化のための目的関数と呼びます。この目的関数が最小になれば、予測値をはじき出す最適なモデルとしてのパラメータ
\(a\)
![]() と
\(b\)
と
\(b\)
![]() が決まり、
\(\tilde{y}_k=a x+b\)
が決まり、
\(\tilde{y}_k=a x+b\)
![]() が得られるわけです。
が得られるわけです。
すべてのデータ
\(e_k\)
![]() の総和を
\(E\)
の総和を
\(E\)
![]() とするとき、
\(E\)
とするとき、
\(E\)
![]() が最小になる条件は前出①のとおりです。
$$\frac{\partial E}{\partial a}=0 \quad \frac{\partial E}{\partial b}=0$$
が最小になる条件は前出①のとおりです。
$$\frac{\partial E}{\partial a}=0 \quad \frac{\partial E}{\partial b}=0$$
![]()
このように最小二乗法は、誤差の総和
\(E\)
![]() を最小化するパラメータを持つモデルが最適という考え方に基づいています。
を最小化するパラメータを持つモデルが最適という考え方に基づいています。
勾配降下法の概念と仕組み
ある関数
\(z=f(x,y)\)
![]() が与えられたとき、その関数が最小になる変数
\(x\)
が与えられたとき、その関数が最小になる変数
\(x\)
![]() 、
\(y\)
、
\(y\)
![]() については「勾配降下法」によって求めることができます。
については「勾配降下法」によって求めることができます。
\(z=f(x,y)\)
![]() が最小になるのは、最小二乗法と同様に下記の条件が満たされた場合です。ここでは関数は2変数なので曲面となり、接平面の傾きがゼロで接する場所を求めることを意味しています。
$$
\frac{\partial f(x,y)}{\partial x}=0 \quad \frac{\partial f(x,y)}{\partial y}=0 \:②
$$
が最小になるのは、最小二乗法と同様に下記の条件が満たされた場合です。ここでは関数は2変数なので曲面となり、接平面の傾きがゼロで接する場所を求めることを意味しています。
$$
\frac{\partial f(x,y)}{\partial x}=0 \quad \frac{\partial f(x,y)}{\partial y}=0 \:②
$$
![]()
例えば、
\(z=f(x,y)=x^2+y^2\)
![]() のときはどうでしょうか?
のときはどうでしょうか?
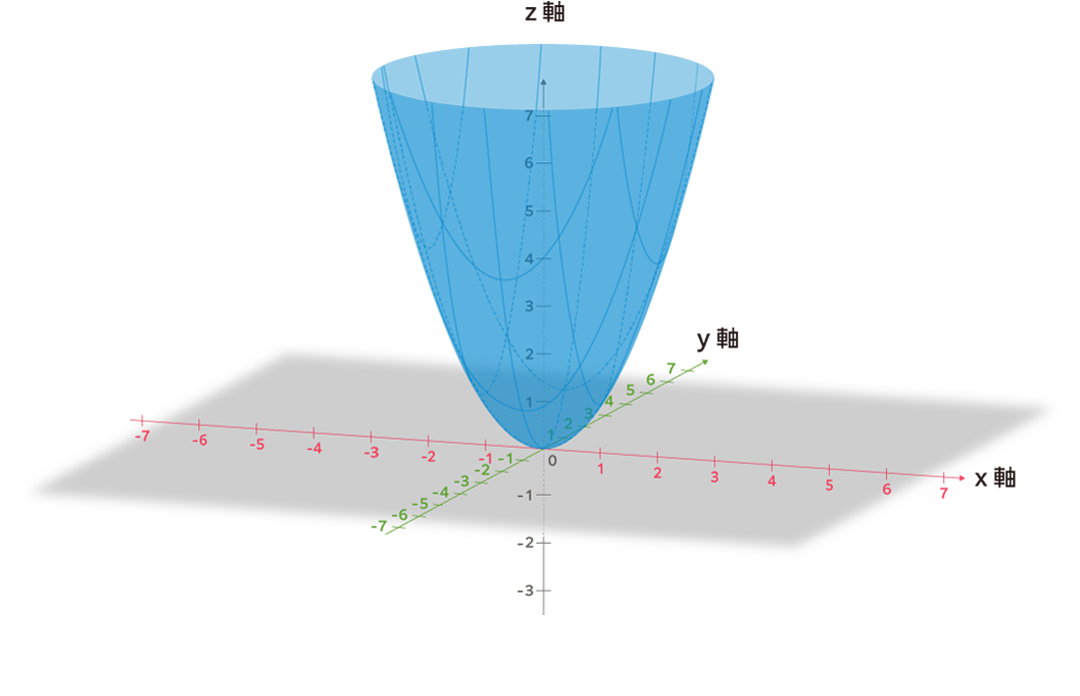
下記の条件にあてはめて計算すると $$ \frac{\partial f(x,y)}{\partial x}=0 \quad \frac{\partial f(x,y)}{\partial y}=0 $$ $$ \frac{\partial f(x^2+y^2)}{\partial x}=0 \quad \frac{\partial f(x^2+y^2)}{\partial y}=0 $$
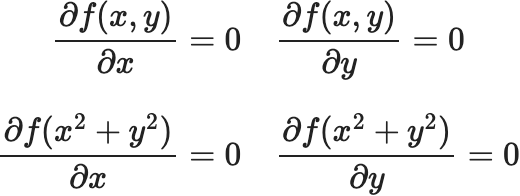
それぞれ
\(2x=0 \;\; 2y=0\)
![]() ですから、この関数が最小になる必要条件は
\(x=0 \;\; y=0\)
ですから、この関数が最小になる必要条件は
\(x=0 \;\; y=0\)
![]() となります。ここで
\(z\)
となります。ここで
\(z\)
![]() は \(0\) になりますが、
\(z\)
は \(0\) になりますが、
\(z\)
![]() は二乗項の和なので
\(z=f(x,y)=x^2+y^2≥0\)
は二乗項の和なので
\(z=f(x,y)=x^2+y^2≥0\)
![]() となるため、
\(z=0\)
となるため、
\(z=0\)
![]() が最小値となります。
が最小値となります。
ここではごく簡単な事例を示しましたが、実際のシーンでは②のような連立方程式はうまく解けないことが多く、その代替として用いられるのが「勾配降下法」です。これは前出のように方程式から答えを導き出すのではなく、グラフ上の点
\((\Delta x,\Delta y)\)
![]() を少しずつ動かしながら関数の最小値を見つけ出すアプローチになります。
を少しずつ動かしながら関数の最小値を見つけ出すアプローチになります。
仮に図のような
\(z\)
![]() 斜面の関数
\(z=f(x,y)\)
斜面の関数
\(z=f(x,y)\)
![]() の上にボールを置いたとすると、ボールは最も急な斜面に沿って
\((\Delta x,\Delta y)\)
の上にボールを置いたとすると、ボールは最も急な斜面に沿って
\((\Delta x,\Delta y)\)
![]() ぶん動いていきます。少し進んだらボールを止めて、そこから再び
\((\Delta x,\Delta y)\)
ぶん動いていきます。少し進んだらボールを止めて、そこから再び
\((\Delta x,\Delta y)\)
![]() だけ動かしていきます。すると同じように最も急な斜面に沿って転がっていきます。これをずっと繰り返すと、最短経路に沿ってボトムの点、すなわち最小点にたどりつくはずです。このような原理に基づいて考えられたのが勾配降下法です。
だけ動かしていきます。すると同じように最も急な斜面に沿って転がっていきます。これをずっと繰り返すと、最短経路に沿ってボトムの点、すなわち最小点にたどりつくはずです。このような原理に基づいて考えられたのが勾配降下法です。
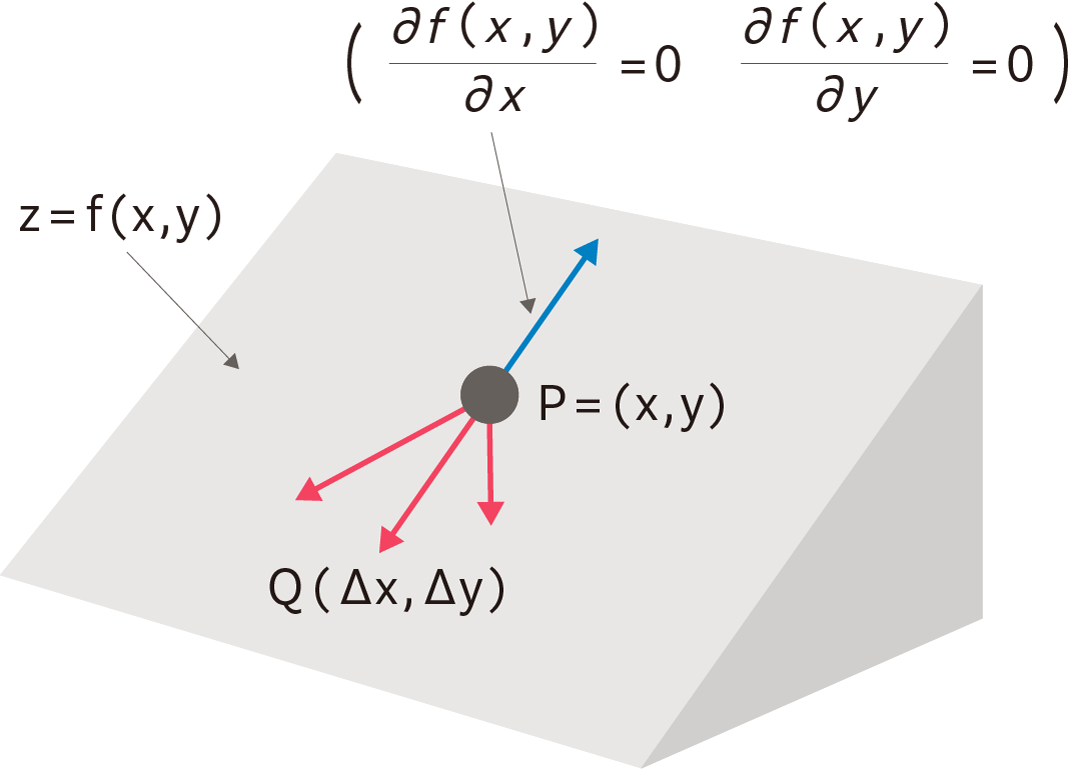
上の図で
\(P\)
![]() 点から
\(Q\)
点から
\(Q\)
![]() 点に
\((\Delta x,\Delta y)\)
点に
\((\Delta x,\Delta y)\)
![]() ぶん移動したとき
\(\Delta z=f(x+\Delta x,y+\Delta y)-f(x,y)\)
ぶん移動したとき
\(\Delta z=f(x+\Delta x,y+\Delta y)-f(x,y)\)
![]() となります。
となります。
細かい式の導出は割愛しますが、この
\(\Delta z\)
![]() は、以下のような近似式で表現できます。
$$\Delta z=\frac{\partial f(x,y)}{\partial x}\Delta x + \frac{\partial f(x,y)}{\partial y}\Delta y$$
は、以下のような近似式で表現できます。
$$\Delta z=\frac{\partial f(x,y)}{\partial x}\Delta x + \frac{\partial f(x,y)}{\partial y}\Delta y$$
![]()
ここで右辺は次のセクションで触れるベクトルの内積の形をしており次のように表現できます。 $$ \left(\frac{\partial f(x, y)}{\partial x} \quad \frac{\partial f(x, y)}{\partial y}\right) \quad,(\Delta \mathrm{x} \Delta \mathrm{y})\;③ $$
![]()
\(\left(\frac{\partial f(x, y)}{\partial x} \quad \frac{\partial f(x, y)}{\partial
y}\right)\)
![]() は、電磁気学などベクトル解析で登場する勾配
\(grad\;f\)
は、電磁気学などベクトル解析で登場する勾配
\(grad\;f\)
![]() のことです。
のことです。
さて、内積の性質についても次のベクトルのセクションで説明しますが、上の
\(PQ\)
![]() ベクトルが最小になるのは反対向きのときです。図のように
\(PR\)
ベクトルが最小になるのは反対向きのときです。図のように
\(PR\)
![]() のときに
\(\Delta z\)
のときに
\(\Delta z\)
![]() が最も減少することになります。そこで下記のような基本式が導き出されます。
が最も減少することになります。そこで下記のような基本式が導き出されます。
$$(\Delta \mathrm{x} \quad \Delta \mathrm{y})=-η\;(\frac{\partial f(x, y)}{\partial x} \quad \frac{\partial f(x, y)}{\partial y})\;④$$
![]()
(
\(η\)
![]() :イータ、定数で学習係数と呼ぶ)
:イータ、定数で学習係数と呼ぶ)
勾配降下法では、この④を利用して、学習係数
\(η\)
![]() を調整しながら、最も減少する方向を探し、何度も同じ操作を試行錯誤して繰り返すことで
\(f(x,y)\)
を調整しながら、最も減少する方向を探し、何度も同じ操作を試行錯誤して繰り返すことで
\(f(x,y)\)
![]() の最小点を探せます。こういった処理はコンピュータに任せることになります。
の最小点を探せます。こういった処理はコンピュータに任せることになります。
エンジニアとしての市場価値を知るために
年収査定を受ける(無料)線形代数(行列)の基礎知識
次に、線形代数について簡単におさらいしましょう。機械学習では大量のデータを扱うことになります。その際にデータ構造を効率よく捉え、変数の関係をシンプルに記述する際に線形代数(行列)が役立ちます。ここでは「スカラー」「ベクトル」「行列」「テンソル」について復習します。
ベクトルの基本、内積とコサイン類似度
整数や小数のように、数値の大きさで表すのが「スカラー」ですが、大きさに加えて方向(向き)を併せ持つのが「ベクトル(ベクター)」です。
ベクトルの表記は、例えばアルファベットの頭に → を付けて、
\(\vec{a}\)
![]() と表記したり、太文字で
\(\boldsymbol {α}\)
と表記したり、太文字で
\(\boldsymbol {α}\)
![]() のように書いたりします。
のように書いたりします。
ベクトルを図で表現するときは、ベクトルの大きさと向きを座標軸の成分に分けて考えます。例えば、以下のような2次元ベクトルを考えましょう。それぞれスカラーの成分に分けて、横に並べて「行ベクトル」を以下のように表現するか、 $$\boldsymbol {α}=(2,1)$$ $$\boldsymbol {β}=(-1,2)$$
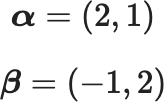
あるいは、縦に並べて「列ベクトル」で表します。 $$ \boldsymbol {α}=\begin{pmatrix}2 \\ 1 \ \end{pmatrix} \boldsymbol {β}=\begin{pmatrix}-1 \\ 2 \ \end{pmatrix} $$
![]()
この2つのベクトルは、平面上では以下のように表現されます。
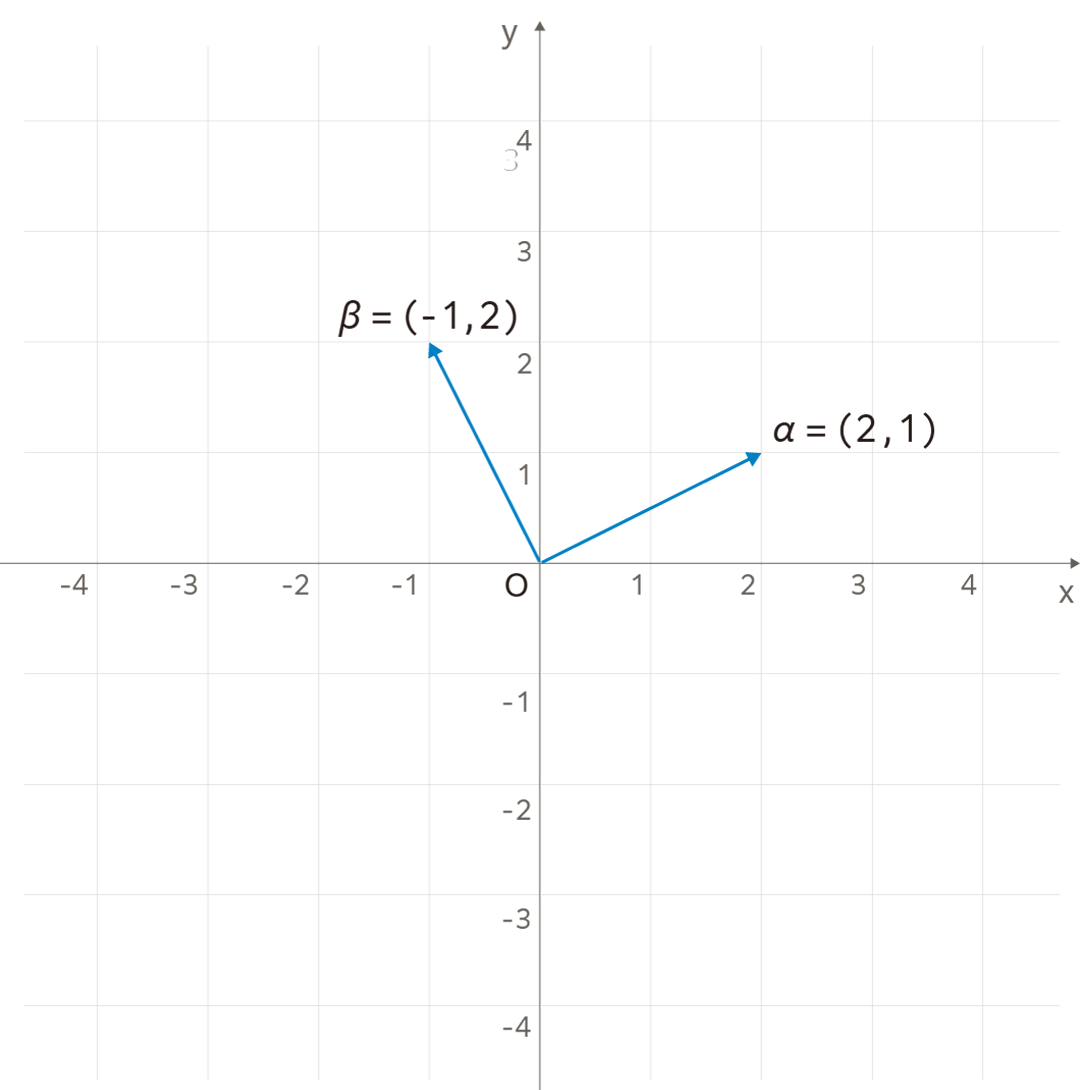
上図のように2つのベクトルがあり、そのなす角を
\(\theta\)
![]() とすると、以下のようにベクトルの内積を定義することができます。
$$\boldsymbol{α・β}=|\boldsymbol{α}|\;|\boldsymbol{β}|cosθ$$
とすると、以下のようにベクトルの内積を定義することができます。
$$\boldsymbol{α・β}=|\boldsymbol{α}|\;|\boldsymbol{β}|cosθ$$
![]()
また、ベクトルを成分表示すると
\(\boldsymbol{α}=(a_1, a_2)\quad \boldsymbol{β}=(b_1,b_2)\)
![]() になります。
になります。
ここで内積は、それぞれ「
\(x\)
![]() 成分同士」と「
\(y\)
成分同士」と「
\(y\)
![]() 成分同士」の積の和で定義されます。
$$\boldsymbol{α・β}=a_1 b_1 +a_2 b_2 $$
$$\boldsymbol{α・α}=a_1 a_1 +a_2 a_2 =a_1^2+a_2^2$$
成分同士」の積の和で定義されます。
$$\boldsymbol{α・β}=a_1 b_1 +a_2 b_2 $$
$$\boldsymbol{α・α}=a_1 a_1 +a_2 a_2 =a_1^2+a_2^2$$
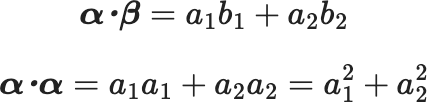
では、上図を例にして2つのベクトルのなす角を調べてみましょう。
2つのベクトルのなす角は、内積の定義から
\(\cos \theta=\frac{\alpha \cdot \beta}{|\alpha||\beta|}\)
![]() となります。
となります。
\(\boldsymbol{\alpha}=(2,1)\quad \boldsymbol{\beta}=(-1,2)\)
![]() ですから、
ですから、
\(\boldsymbol{\alpha} \cdot \boldsymbol{\beta}=a_{1} b_{1}+a_{2} b_{2}=2 \cdot-1+1 \cdot
2=0\)
![]()
次に、
\(\boldsymbol{\alpha}\)
![]() と
\(\boldsymbol{\beta}\)
と
\(\boldsymbol{\beta}\)
![]() の長さは、
\(|\boldsymbol{\alpha}|\)
の長さは、
\(|\boldsymbol{\alpha}|\)
![]() と
\(|\boldsymbol{\beta}|\)
と
\(|\boldsymbol{\beta}|\)
![]() は三平方の定理からいずれも
\(|\boldsymbol{\alpha}|=\sqrt{5} \quad|\boldsymbol{\beta}|=\sqrt{5}\)
は三平方の定理からいずれも
\(|\boldsymbol{\alpha}|=\sqrt{5} \quad|\boldsymbol{\beta}|=\sqrt{5}\)
![]() となるため
$$
\cos \theta=\frac{\boldsymbol{\alpha} \cdot
\boldsymbol{\beta}}{|\boldsymbol{\alpha}||\boldsymbol{\beta}|}=\frac{0}{\sqrt{5} * \sqrt{5}}=0
$$
となるため
$$
\cos \theta=\frac{\boldsymbol{\alpha} \cdot
\boldsymbol{\beta}}{|\boldsymbol{\alpha}||\boldsymbol{\beta}|}=\frac{0}{\sqrt{5} * \sqrt{5}}=0
$$
![]()
\(\cos \theta=0\)
![]() (
\(\theta\)
(
\(\theta\)
![]() は2つのベクトルがなす角)は90°ですから、2つのベクトル
\(\boldsymbol{\alpha}\)
は2つのベクトルがなす角)は90°ですから、2つのベクトル
\(\boldsymbol{\alpha}\)
![]() と
\(\boldsymbol{\beta}\)
と
\(\boldsymbol{\beta}\)
![]() が直交していることが分かります。
が直交していることが分かります。
内積を詳しく説明してきましたが、その理由のひとつは、内積がデータの類似性を調べるのに役立つからです。これは「コサイン類似度」と呼ばれていますが、2つのベクトルの内積を2つのベクトルの大きさで割ることで計算でき、その値は-1 ~ +1の範囲で正規化されます。
そのときの値が「1」なら、2つのベクトルのなす角は0°なので同じ向きのベクトルになり、「一致している」ことになります。また「0」なら先の事例のように各ベクトルのなす角は90°で、独立/直交した向きのベクトルとなり無関係、「-1」なら-180°で反対向きのベクトルとなり「類似性がない」という意味になります。
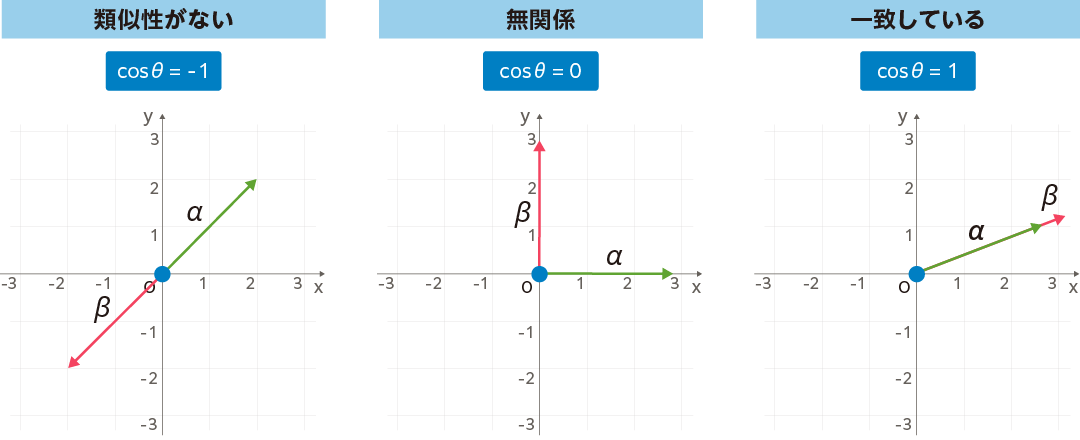
コサイン類似度は、例えば2つの文章を構成する単語を数値によるベクトルに置き換えて計算すれば、文章の類似性を評価できるようになります。また画像/動画での姿勢推定への応用や、機械学習のモデルの良さを測るための評価関数でも使われます。
ベクトルによる微分と勾配
じつはベクトルも微分することができます。微分は、ある関数における変化の割合を示すものです。したがって関数の入力がベクトルである場合に微分が適用できます。具体的には関数のベクトル成分ごとに偏微分します。それらを並べてベクトルにしたものを「勾配」と呼びます。
例えば
\(\boldsymbol{\alpha}=\left(\begin{array}{c}8 \\ 12\end{array}\right) \quad
\boldsymbol{X}=\left(\begin{array}{l}x_{1} \\ x_{2}\end{array}\right) \quad\)
![]() とし、
\(\boldsymbol{\alpha}^{\mathrm{T}}=(8,12)\)
とし、
\(\boldsymbol{\alpha}^{\mathrm{T}}=(8,12)\)
![]() に変形すると
$$
\boldsymbol{\alpha}^{\mathrm{T}} \boldsymbol{X}=(8,12)\left(\begin{array}{l}
x_{1} \\
x_{2}
\end{array}\right)=8 x_{1}+12 x_{2}
$$
に変形すると
$$
\boldsymbol{\alpha}^{\mathrm{T}} \boldsymbol{X}=(8,12)\left(\begin{array}{l}
x_{1} \\
x_{2}
\end{array}\right)=8 x_{1}+12 x_{2}
$$
![]()
これを
\(\frac{\partial}{\partial x}\left(\boldsymbol{a}^{\mathrm{T}}
\boldsymbol{X}\right)\)
![]() をベクトルで微分するといいます。
をベクトルで微分するといいます。
以下、具体的に計算してみましょう。 $$ \begin{eqnarray} \frac{\partial}{\partial_{X}}\left(\boldsymbol{\alpha}^{\mathrm{T}} \boldsymbol{X}\right) &=&\frac{\partial}{\partial_{X}}\left(8 x_{1}+12 x_{2}\right)\\ &=&\left(\begin{array}{l} \frac{\partial}{\partial_{X_{1}}}\left(8 x_{1}+12 x_{2}\right) \\ \frac{\partial}{\partial_{X_{2}}}\left(8 x_{1}+12 x_{2}\right) \end{array}\right) \end{eqnarray} $$
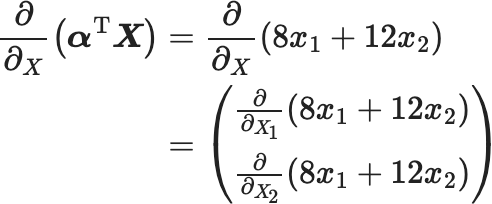
各成分について計算すると $$ \begin{eqnarray} \frac{\partial}{\partial_{X_{1}}}\left(8 x_{1}+12 x_{2}\right)&=&\frac{\partial}{\partial_{X_{1}}}\left(8 x_{1}\right)+\frac{\partial}{\partial_{X_{1}}}\left(12 x_{2}\right)\\ &=&8 \\ \frac{\partial}{\partial_{X_{2}}}\left(8 x_{1}+12 x_{2}\right)\ &=&\frac{\partial}{\partial_{X_{2}}}\left(8 x_{1}\right)+\frac{\partial}{\partial_{X_{2}}}\left(12 x_{2}\right)\\ &=&12 \end{eqnarray} $$
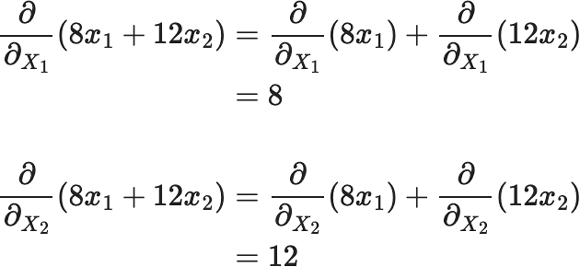
したがって $$ \frac{\partial}{\partial_{X}}\left(\boldsymbol{\alpha}^{\mathrm{T}} \boldsymbol{X}\right)=\left(\begin{array}{c} 8 \\ 12 \end{array}\right)=\boldsymbol{\alpha} $$
![]()
が得られます。
行列の基本
ベクトルは1行または1列の並びですが、横方向・縦方向に複数のベクトルを並べたものが「行列」になります。行列は
\(\boldsymbol{A}\)
![]() のように大文字アルファベットの太字で表し、各要素はカッコの中に記述します。例えば、2行2列の行列は
$$
\boldsymbol{A}=\left(\begin{array}{ll}
X_{11} & X_{12} \\
X_{21} & X_{22}
\end{array}\right)
$$
のように大文字アルファベットの太字で表し、各要素はカッコの中に記述します。例えば、2行2列の行列は
$$
\boldsymbol{A}=\left(\begin{array}{ll}
X_{11} & X_{12} \\
X_{21} & X_{22}
\end{array}\right)
$$
![]()
のような形になります。
ここで、上の行列のように、行と列の数が同じものを「正方行列」と呼びます。
また、行と列を入れ替える操作を「転置」と呼び、大文字・太字の
\(\mathrm{T}\)
![]() で表します。
で表します。
例えば、ベクトル
\(\boldsymbol{A}=(1,2,3)\)
![]() の転置
\(\boldsymbol{A}^{\mathrm{T}}\)
の転置
\(\boldsymbol{A}^{\mathrm{T}}\)
![]() は
\(\left(\begin{array}{l}1 \\ 2 \\ 3\end{array}\right)\)
は
\(\left(\begin{array}{l}1 \\ 2 \\ 3\end{array}\right)\)
![]() となります。
となります。
転置で押さえたい公式は次のとおりです。
\(\left(\boldsymbol{A}^{\mathrm{T}}\right)^{\mathrm{T}}=\boldsymbol{A}\)
![]() (転置の転置なので元に戻る)
(転置の転置なので元に戻る)
\((\boldsymbol{A B})^{\mathrm{T}}=\boldsymbol{B}^{\mathrm{T}}
\boldsymbol{A}^{\mathrm{T}}\)
![]() (計算の順が逆になるので注意)
(計算の順が逆になるので注意)
次にテンソルです。これはベクトルや行列を一般化した概念です。例えば、ベクトルは1階のテンソル、行列は2階のテンソル、それ以上の多次元をまとめて「テンソル」と呼んでいます。テンソルは物理学の分野世界でさまざまに利用されています。
ベクトルや行列の基本演算の復習
ベクトルや行列では、行と列が同じサイズであれば、各要素で加減算が成立します。
ベクトルの場合は
$$ \begin{eqnarray} \left(\begin{array}{l} 1 \\ 2 \\ 3 \end{array}\right)+\left(\begin{array}{l} 1 \\ 2 \\ 3 \end{array}\right) &=&\left(\begin{array}{l} 1+1 \\ 2+2 \\ 3+3 \end{array}\right)\\ &=& \left(\begin{array}{l} 2 \\ 4 \\ 6 \end{array}\right)\\ &=&2\left(\begin{array}{l} 1 \\ 2 \\ 3 \end{array}\right) \\ \left(\begin{array}{l} 1 \\ 2 \\ 3 \end{array}\right)-\left(\begin{array}{l} 1 \\ 2 \\ 3 \end{array}\right) &=&\left(\begin{array}{l} 0 \\ 0 \\ 0 \end{array}\right)\\ &=&0 \quad \text (ゼロベクトル) \end{eqnarray} $$
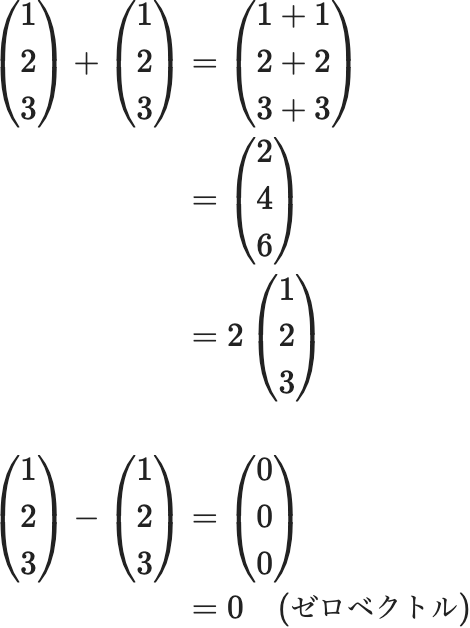
行列の場合は
$$ \begin{eqnarray} \left(\begin{array}{ll} 1 & 2 \\ 3 & 4 \end{array}\right)+\left(\begin{array}{ll} 5 & 6 \\ 7 & 8 \end{array}\right)&=&\left(\begin{array}{ll} 1+5 & 2+6 \\ 3+7 & 4+8 \end{array}\right)\\ &=&\left(\begin{array}{cc} 6 & 8 \\ 10 & 12 \end{array}\right)\\ &=&2\left(\begin{array}{ll} 3 & 4 \\ 5 & 6 \end{array}\right) \end{eqnarray} $$

のようになります。
ちなみに、各要素がゼロになった場合のベクトルをゼロベクトル、行列をゼロ行列と呼びます。
行列
\(\boldsymbol{A}\)
![]() \(\boldsymbol{B}\)
\(\boldsymbol{B}\)
![]() の乗算は、演算の法則があるので注意しましょう。
の乗算は、演算の法則があるので注意しましょう。
もっとも単純な行列(ベクトル)の乗算は
$$
\left(\begin{array}{ll}
a & b
\end{array}\right)\left(\begin{array}{l}
c \\
d
\end{array}\right)=a c+b d
$$
![]()
これに倣って、行列
\(\boldsymbol{A}\)
![]() と
\(\boldsymbol{B}\)
と
\(\boldsymbol{B}\)
![]() の積は、
\(\boldsymbol{A}\)
の積は、
\(\boldsymbol{A}\)
![]() の各行と
\(\boldsymbol{B}\)
の各行と
\(\boldsymbol{B}\)
![]() の各列の内積を並べたものになります。
の各列の内積を並べたものになります。
$$ \begin{eqnarray} \left(\begin{array}{ll} 1 & 2 \\ 3 & 4 \end{array}\right)\left(\begin{array}{ll} 5 & 6 \\ 7 & 8 \end{array}\right)&=&\left(\begin{array}{ll} 1 \times 5+2 \times 7 & 1 \times 6+2 \times 8 \\ 3 \times 5+4 \times 7 & 3 \times 6+4 \times 8 \end{array}\right)\\ &=&\left(\begin{array}{ll} 19 & 22 \\ 43 & 50 \end{array}\right) \end{eqnarray} $$
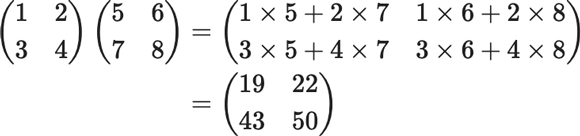
行列の乗算が成立するためには、
\(\boldsymbol{A}\)
![]() の行サイズと
\(\boldsymbol{B}\)
の行サイズと
\(\boldsymbol{B}\)
![]() の列サイズが等しいことが条件になります。またスカラー積のように交換法則は成り立ちません。つまり
\(\boldsymbol{A B} \neq \boldsymbol{B A}\)
の列サイズが等しいことが条件になります。またスカラー積のように交換法則は成り立ちません。つまり
\(\boldsymbol{A B} \neq \boldsymbol{B A}\)
![]() なので注意しましょう。
なので注意しましょう。
なお、行列
\(\boldsymbol{A}\)
![]() \(\boldsymbol{B}\)
\(\boldsymbol{B}\)
![]() の割り算にあたる演算子はありませんが、例えば
\(10 \div 5=10 \times \frac{1}{5}\)
の割り算にあたる演算子はありませんが、例えば
\(10 \div 5=10 \times \frac{1}{5}\)
![]() のように、逆数と同じ考え方で、次に説明する逆行列を掛けることで、結果的に除算を行うことができます。
のように、逆数と同じ考え方で、次に説明する逆行列を掛けることで、結果的に除算を行うことができます。
ベクトルの単位行列と逆行列
行列には数字の1のように、任意の行列を掛けても同じ結果になる単位行列
\(\boldsymbol{I}\)
![]() が存在します。
が存在します。
例えば、3×3の行列なら
$$ E=\left(\begin{array}{lll} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array}\right) $$
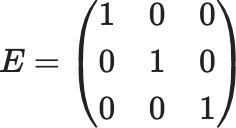
のように、行列の斜めの対角要素がすべて1で、それ以外の非対角要素が0になる正方行列が単位行列となり、
\(\boldsymbol{E}\)
![]() で表されます。
で表されます。
単位行列ではある正方行列
\(\boldsymbol{A}\)
![]() に対して
$$
A E=E A=A
$$
に対して
$$
A E=E A=A
$$
![]()
という関係が成立します。
前述の逆行列は、単位行列を
\(\boldsymbol{E}\)
![]() 、正方行列を
\(\boldsymbol{A}\)
、正方行列を
\(\boldsymbol{A}\)
![]() としたとき
\(\boldsymbol{A} \boldsymbol{X}=\boldsymbol{X} \boldsymbol{A}=\boldsymbol{E}\)
としたとき
\(\boldsymbol{A} \boldsymbol{X}=\boldsymbol{X} \boldsymbol{A}=\boldsymbol{E}\)
![]() となる行列
\(\boldsymbol{X}\)
となる行列
\(\boldsymbol{X}\)
![]() のことで
\(\boldsymbol{A}^{-1}\)
のことで
\(\boldsymbol{A}^{-1}\)
![]() (
\(\boldsymbol{A}\)
(
\(\boldsymbol{A}\)
![]() のインバース)と表記します。
のインバース)と表記します。
証明は割愛しますが、
\(\boldsymbol{A}=\left(\begin{array}{ll}a & b \\ c & d\end{array}\right)\)
![]() の逆行列は以下のようになります(逆行列を持つ行列を正則行列という)。
の逆行列は以下のようになります(逆行列を持つ行列を正則行列という)。
$$ \boldsymbol{A}^{-1}=\frac{1}{a d-b c}\left(\begin{array}{cc} d & -b \\ -c & a \end{array}\right) $$
![]()
ここで
\(\Delta=a d-b c \neq 0\)
![]() のとき上式が成立します。
のとき上式が成立します。
また、
\(\Delta=a d-b c=0\)
![]() のときは上式は成立せず、逆行列は存在しません。
のときは上式は成立せず、逆行列は存在しません。
逆行列の性質を簡単にまとめると
$$ \begin{gathered}①\quad \boldsymbol{A} \boldsymbol{A}^{-1}=\boldsymbol{A}^{-1} \boldsymbol{A}=\boldsymbol{E} \\ ②\quad \boldsymbol{A} \boldsymbol{X}=\boldsymbol{E} \text { のとき } \boldsymbol{X}=\boldsymbol{A}^{-1} \\ \boldsymbol{X} \boldsymbol{A}=\boldsymbol{E} \text { のとき } \boldsymbol{X}=\boldsymbol{A}^{-1} \end{gathered} $$

連立方程式の解
逆行列を利用して、以下のように連立方程式の解を求めることができます。
例えば、以下のような方程式が与えられたとき
$$ \begin{aligned} & 4 x+5 y=14 \\ & -x+5 y=5 \end{aligned} $$
![]()
上の式を行列を使って表現すると
\(\left(\begin{array}{cc}4 & 5 \\ -1 & 3\end{array}\right)\left(\begin{array}{l}x \\
y\end{array}\right)=\left(\begin{array}{c}14 \\ 5\end{array}\right)\)
![]() となります
となります
ここで両辺に
\(\left(\begin{array}{cc}4 & 5 \\ -1 & 3\end{array}\right)\)
![]() の逆行列
\(\left(\begin{array}{cc}4 & 5 \\ -1 & 3\end{array}\right)^{-1}\)
の逆行列
\(\left(\begin{array}{cc}4 & 5 \\ -1 & 3\end{array}\right)^{-1}\)
![]() を左から掛けます。
を左から掛けます。
$$ \left(\begin{array}{cc} 4 & 5 \\ -1 & 3 \end{array}\right)^{-1}\left(\begin{array}{cc} 4 & 5 \\ -1 & 3 \end{array}\right)\left(\begin{array}{l} x \\ y \end{array}\right)=\left(\begin{array}{cc} 4 & 5 \\ -1 & 3 \end{array}\right)^{-1}\left(\begin{array}{c} 14 \\ 5 \end{array}\right) $$
![]()
\(\left(\begin{array}{cc}4 & 5 \\ -1 & 3\end{array}\right)^{-1}\left(\begin{array}{cc}4
& 5 \\ -1 & 3\end{array}\right)\)
![]() は単位行列
\(\left(\begin{array}{ll}1 & 0 \\ 0 & 1\end{array}\right)\)
は単位行列
\(\left(\begin{array}{ll}1 & 0 \\ 0 & 1\end{array}\right)\)
![]() となり、
となり、
$$ \begin{eqnarray} \left(\begin{array}{ll} 1 & 0 \\ 0 & 1 \end{array}\right)\left(\begin{array}{c} x \\ y \end{array}\right)&=&\left(\begin{array}{cc} 4 & 5 \\ -1 & 3 \end{array}\right)^{-1}\left(\begin{array}{c} 14 \\ 5 \end{array}\right) \\ \left(\begin{array}{l} x \\ y \end{array}\right)&=& \left(\begin{array}{cc} 4 & 5 \\ -1 & 3 \end{array}\right)^{-1}\left(\begin{array}{c} 14 \\ 5 \end{array}\right)\\ &=&\frac{1}{4 * 3-5 *(-1)}\left(\begin{array}{cc} 3 & -5 \\ 1 & 4 \end{array}\right)\left(\begin{array}{c} 14 \\ 5 \end{array}\right)\\ &=&\left(\begin{array}{l} 1 \\ 2 \end{array}\right) \end{eqnarray} $$
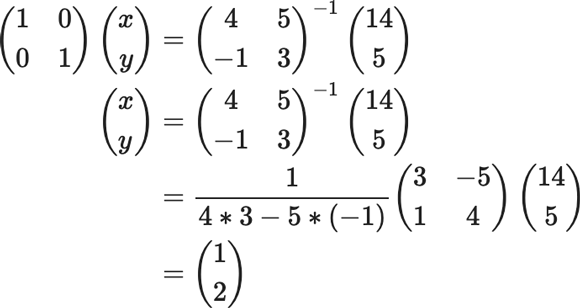
となり、
\(x=1 \quad y=2\)
![]() が求まります。
が求まります。
行列は、連立一次方程式を解く「掃き出し法」のように、単純な操作を高速で繰り返すコンピュータとの親和性が高いため、さまざまなアルゴリズムで役立ちます。機械学習の場合、ニューラルネットワークの計算はもちろん、重回帰分析のように変数が多くなる場合には、行列の知識は必須になります。
例えば、
\(y=a_{0} x_{0}+a_{1} x_{1}+a_{2} x_{2}+\cdots+a_{m} x_{m}\)
![]() のような多項式を下記のように表現し、計算をラクにしてくれます。
のような多項式を下記のように表現し、計算をラクにしてくれます。
$$ =\left(\begin{array}{llll} a_{0} & a_{1} & a_{2} & \ldots+a_{m} \end{array}\right)\left(\begin{array}{c} x_{0} \\ x_{1} \\ \cdot \\ \cdot \\ \cdot \\ x_{m} \end{array}\right)=\boldsymbol{A}^{\mathrm{T}} \boldsymbol{X} $$

エンジニアとしての市場価値を知るために
年収査定を受ける(無料)数列、統計の基礎知識
機械学習の数学では、前述のように微分と線形代数(行列)をマスターしていれば、アルゴリズムを理解することができます。では、なぜ確率・統計の知識も必要なのでしょうか? もともと機械学習の手法は「統計的機械学習」といわれるように、統計を基礎に構築されているからです。
機械学習の目的は、法則を捉えて最適なモデルを導き出すことです。その際に大量のデータを使います。すべてのデータを使えない場合は、ある集団のデータの一部をサンプルとして取ります。
ただし、データの中には利用できないデータも少なからず存在し、それらのデータが妥当か判断したり、もし外れ値があれば、それらのデータを除外する必要もあります。このように機械学習を行う際には、きれいにクレンジングしたり、使いやすいように正規化するなどの前処理が求められます。機械学習の工程では前処理に非常に時間を割きます。そのようなときに確率・統計の知識が役立つことになります。
また、データを集計する際には数列の考え方も重要になるため、本セクションの冒頭で触れた数例についても説明しておきます。
数列とは何か?
1,6,11,16,21,26,… のように、数が列挙されたものを「数列」と呼びます。この数字を眺めていると、ある規則性に気づくでしょう。最初の数字(初項)から、次の数字(各数字を項という)まで、5ずつ増えています。この間隔が「公差」で、隣り合う項の差が等しい数列を「等差数列」と呼びます。
この数列の第
\(n\)
![]() 項を一般式で表すと、
\(a_{n}=1+5 \times(n-1)\)
項を一般式で表すと、
\(a_{n}=1+5 \times(n-1)\)
![]() となります。
となります。
初項
\(a\)
![]() 、公差
\(d\)
、公差
\(d\)
![]() として、第
\(n\)
として、第
\(n\)
![]() 項を表す一般式にすると、以下のような形で表現できます。
$$
a_{n}=a+d \times(n-1)
$$
項を表す一般式にすると、以下のような形で表現できます。
$$
a_{n}=a+d \times(n-1)
$$
![]()
次に、数列
\(a_{n}=a+d \times(n-1)\)
![]() の第
\(n\)
の第
\(n\)
![]() 項までの和を求めてみましょう。
項までの和を求めてみましょう。
例えば、
\(a=1 \quad d=1 \quad n=10\)
![]() の計算は、以下のようにすると簡単に求まります。
$$①\quad 1+2+3+4+5+6+7+8+9+10=55$$
$$②\quad 10+9+8+7+6+5+4+3+2+1=55$$
の計算は、以下のようにすると簡単に求まります。
$$①\quad 1+2+3+4+5+6+7+8+9+10=55$$
$$②\quad 10+9+8+7+6+5+4+3+2+1=55$$
![]()
とし、
①の各項と②の各項を足すと
$$
\begin{eqnarray}③\quad 11+11+11+11+11+11+11+11+11+11 &=& 11 \times 10\
&=& 110
\end{eqnarray}
$$
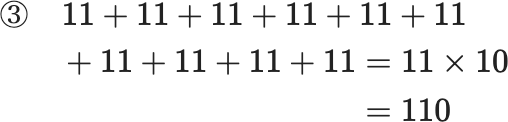
③のように各項の和が11となり、総計は11×10(項数)=110 と簡単に求まります。 ここでは①の数列を2つ用意したので、元の答えは、110の半分の55になるわけです。
この等差数列の総和を
\(\Sigma\)
![]() 記号を使って以下のように一般化します。
$$
\begin{gathered}
\text { ④ } a+(a+d)+\ldots+\{(a+(n-1) d)\} \\
\text { ⑤ }\{(a+(n-1) d)\}+\{(a+(n-2) d)\}+\cdots+a \\ \\
\text { ④ }+ \text { ⑤ }\{2 a+(n-1) d\}+\{2 a+(n-1) d\}+\cdots+\{2 a+(n-1) d\}
\end{gathered}
$$
記号を使って以下のように一般化します。
$$
\begin{gathered}
\text { ④ } a+(a+d)+\ldots+\{(a+(n-1) d)\} \\
\text { ⑤ }\{(a+(n-1) d)\}+\{(a+(n-2) d)\}+\cdots+a \\ \\
\text { ④ }+ \text { ⑤ }\{2 a+(n-1) d\}+\{2 a+(n-1) d\}+\cdots+\{2 a+(n-1) d\}
\end{gathered}
$$
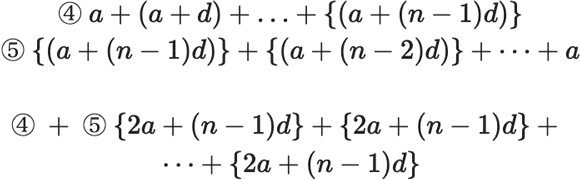
したがって $$ S_{n}=\sum_{k=1}^{n} a_{k}=\frac{n}{2}\{2 a+(n-1) d\} $$
![]()
\(k=1\)
![]() から
\(n\)
から
\(n\)
![]() まで、
\(k\)
まで、
\(k\)
![]() の値を変化させながら、総和を取るという意味です。
の値を変化させながら、総和を取るという意味です。
ここでは等差数列の和の一番簡単な例を挙げましたが、隣り合う項の比が等しい等比数列の場合は次式のように表され、その総和は条件別に以下のようになります。
\( \begin{gathered} S_{n}=\sum_{k-1}^{n} a r^{n-1}=a+a r+a r^{2}+\cdots+a r^{n-1}+\cdots(a r \neq 0) \\ \end{gathered} \) \( \begin{gathered} |r|<\; 1 \text { のとき収束 }\quad S_{n}=\sum_{k-1}^{n} a r^{n-1}=\frac{a}{1-r} \\ \end{gathered} \) \( \begin{gathered} |r| \geq 1 \text { のとき発散 } \end{gathered} \)

数列や漸化式は、機械学習(ニューラルネットワークの誤差逆伝搬法など)でも役立ちます。
エンジニアとしての市場価値を知るために
年収査定を受ける(無料)統計の基礎の基礎、「平均」「分散」「標準偏差」とは?
次に統計の基礎の基礎について簡単に説明します。最低限押さえたい統計量のキーワードは「平均」「分散」「標準偏差」および「確率分布」「正規分布」です。
統計量を求めるときは、「母集団」から「標本集団」を抽出することになります。母集団とは、解析をしたい想定範囲でのデータがすべてそろっているもので、標本集団は母集団の一部を取り出したものになります。サンプル数が多い母集団では、そこから標本集団を無作為(ランダム)に抽出すれば、統計量にほとんど差異がでないため、現実的な方法として標本集団を使います。そこで一部のサンプル(標本)を使って全体の様子を調べることができます。
つまり、母集団からサンプルとして標本を抽出し、その平均値や分散を求めて、母集団の平均、すなわち母平均や母分散を推測することができます。母平均は
\(\mu\)
![]() で表現します。ご存じのとおり、平均はサンプルとして取り出した数値の和をサンプル数の
\(n\)
で表現します。ご存じのとおり、平均はサンプルとして取り出した数値の和をサンプル数の
\(n\)
![]() で割ったものです。平均はデータ分布における「重心」に相当するものになります。例えば、前出の数列で利用したデータを使って説明すると
$$
①\quad 1+2+3+4+5+6+7+8+9+10
$$
で割ったものです。平均はデータ分布における「重心」に相当するものになります。例えば、前出の数列で利用したデータを使って説明すると
$$
①\quad 1+2+3+4+5+6+7+8+9+10
$$
![]()
の平均は
\(\frac{1+2+3+4+5+6+7+8+9+10}{10}=5.5\)
![]() となります。
となります。
一般化すると 平均
\(\bar{x}\)
![]() は
$$
\begin{eqnarray}
\bar{x}&=&\frac{x_{1}+x_{2}+x_{3}+x_{4}+x_{5}+\cdots +x_{n}}{n}\\&=&\frac{1}{n} \sum_{n=1}^{n} x_{n}
\end{eqnarray}
$$
は
$$
\begin{eqnarray}
\bar{x}&=&\frac{x_{1}+x_{2}+x_{3}+x_{4}+x_{5}+\cdots +x_{n}}{n}\\&=&\frac{1}{n} \sum_{n=1}^{n} x_{n}
\end{eqnarray}
$$

となります。
分散は「データのばらつき具合」を表す指標で、標本分散があります。また分散は「各データから平均
\(\mu\)
![]() の差(偏差)を取って、それらを二乗した和の平均値」です。
$$
\text { 標本分散 } \quad \sigma^{2}=\frac{1}{n} \sum_{n=1}^{n}\left(x_{n}-\bar{x}\right)^{2}
$$
の差(偏差)を取って、それらを二乗した和の平均値」です。
$$
\text { 標本分散 } \quad \sigma^{2}=\frac{1}{n} \sum_{n=1}^{n}\left(x_{n}-\bar{x}\right)^{2}
$$
![]()
式から分かるように、分散は2乗した値で、そのままだと単位(次元)も2乗になります。そこで値の平方根を取り、次元が同じになるようにします。例えば長さ
\(m\)
![]() なら、
\(m^2\)
なら、
\(m^2\)
![]() から
\(√\)
から
\(√\)
![]() で元の次元に戻すわけです。この値が標準偏差
\(σ\)
で元の次元に戻すわけです。この値が標準偏差
\(σ\)
![]() になります。なお分散は、上記の「二乗の平均」と「平均の二乗」の差でも計算できます。こちらのほうが計算が楽になります。
$$
\sigma^{2}=\frac{1}{n} \sum_{n=1}^{n} x_{n}{ }^{2}-\left(\frac{1}{n} \sum_{n=1}^{n} x_{n}\right)^{2}
$$
になります。なお分散は、上記の「二乗の平均」と「平均の二乗」の差でも計算できます。こちらのほうが計算が楽になります。
$$
\sigma^{2}=\frac{1}{n} \sum_{n=1}^{n} x_{n}{ }^{2}-\left(\frac{1}{n} \sum_{n=1}^{n} x_{n}\right)^{2}
$$

確率変数と確率分布
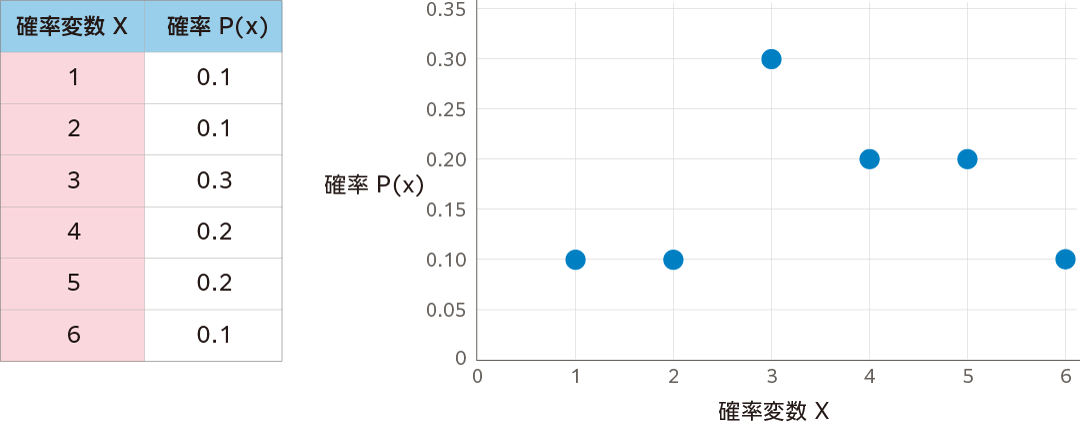
確率は、中学・高校で習いますが、ここでは数学的に厳密な定義をせずに、ある対象とする現象の中で、ランダムな出来事、すなわち事象(イベント)が起きるとき、それらがどの程度起きそうなのかという度合いとして考えます。その確率に従って「確率変数」(random variable)を考えます。確率変数とは、例えばコイントスでコインを投げて表か裏か、それぞれ1/0に変換する関数を考えたとき、1/0のどちらかを取り得ることから、単に確率と呼ばずに確率変数と表現しています。確率変数は、起き得る事象のどれかを取る変数です。確率変数には離散型と連続型があります。具体例としてサイコロを挙げると、これは離散型確率変数になります。
サイコロを投げて出た目の数値に対応させる確率変数
\(X\)
![]() があるとします。ただし、このサイコロは正方形でなく、少しゆがんだイカサマ用のサイコロなので、偏った目が出るとしましょう。このとき確率変数
\(X\)
があるとします。ただし、このサイコロは正方形でなく、少しゆがんだイカサマ用のサイコロなので、偏った目が出るとしましょう。このとき確率変数
\(X\)
![]() の確率を
\(P (X)\)
の確率を
\(P (X)\)
![]() と表現し、以下のような表で確率分布を示します。
と表現し、以下のような表で確率分布を示します。
なお、確率分布には重要な性質が2つあります。
1つ目は「確率変数がとり得るあらゆる値の確率の総和は必ず 1 になる」すなわち $$ \sum_{X} P(X)=1 $$
![]()
2つ目は「すべての確率は 0 以上の値である」すなわち $$ \forall_{X}, P(X) \geq 0 $$
![]()
(
\(\forall_{X}\)
![]() は、あり得る
\(X\)
は、あり得る
\(X\)
![]() の値すべてにおいて、右の条件
\((P(X) \geq 0)\)
の値すべてにおいて、右の条件
\((P(X) \geq 0)\)
![]() が成り立つということです)
が成り立つということです)
ここでサイコロを何回か振ったとき、確率変数が平均して出す値、期待値
\(E=(X)\)
![]() も調べてみましょう。
$$
\begin{eqnarray}
E(X)&=&\sum_{k}^{n} X_{k} P_{k}\\&=&1 \times 0.1+2 \times 0.1+3 \times 0.3+4 \times 0.2+5 \times 0.2+6
\times 0.1\\
&=&3.6
\end{eqnarray}
$$
も調べてみましょう。
$$
\begin{eqnarray}
E(X)&=&\sum_{k}^{n} X_{k} P_{k}\\&=&1 \times 0.1+2 \times 0.1+3 \times 0.3+4 \times 0.2+5 \times 0.2+6
\times 0.1\\
&=&3.6
\end{eqnarray}
$$
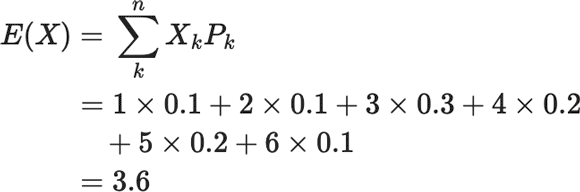
となります。
同時確率と条件付き確率とは?
次に2つの事象
\(A\)
![]() と
\(B\)
と
\(B\)
![]() があるとき、それらが同時に起こる確率「同時確率」を考えましょう。これは
\(P(A \cap B)\)
があるとき、それらが同時に起こる確率「同時確率」を考えましょう。これは
\(P(A \cap B)\)
![]() のように表現します。例えば2個のサイコロを振ったとき、1つ目のサイコロで3の倍数が出る事象
\(A\)
のように表現します。例えば2個のサイコロを振ったとき、1つ目のサイコロで3の倍数が出る事象
\(A\)
![]() と、2つ目のサイコロで奇数の目が出る事象
\(B\)
と、2つ目のサイコロで奇数の目が出る事象
\(B\)
![]() とすると、事象
\(A\)
とすると、事象
\(A\)
![]() と
\(B\)
と
\(B\)
![]() が出る同時確率はどうなるでしょうか。
が出る同時確率はどうなるでしょうか。
ここで一方の事象が他方の事象に影響を与えない場合、事象
\(A\)
![]() と
\(B\)
と
\(B\)
![]() は独立であり、
\(P(A \cap B) =P(A) \times P(B)\)
は独立であり、
\(P(A \cap B) =P(A) \times P(B)\)
![]() が成り立つため、
$$
P(A \cap B)=\frac{2}{6} \times \frac{3}{6}=\frac{1}{6}
$$
が成り立つため、
$$
P(A \cap B)=\frac{2}{6} \times \frac{3}{6}=\frac{1}{6}
$$
![]()
となります。
次に条件付き確率を考えましょう。これは、ある事象
\(A\)
![]() が起きたとき、その条件下で事象
\(B\)
が起きたとき、その条件下で事象
\(B\)
![]() が起きる確率で、
\(P(B \mid A)\)
が起きる確率で、
\(P(B \mid A)\)
![]() と表現します。条件付き確率は、よくスパムメールの振り分けに利用されます。
と表現します。条件付き確率は、よくスパムメールの振り分けに利用されます。
さて、この条件付き確率は、前出の同時確率を使って表現できます。右辺の意味もある事象 \(A\)
![]() が起きたとき、その条件下で事象
\(B\)
が起きたとき、その条件下で事象
\(B\)
![]() が起きる確率と同じです。
$$
P(B \mid A)=\frac{P(A \cap B)}{P(A)}
$$
が起きる確率と同じです。
$$
P(B \mid A)=\frac{P(A \cap B)}{P(A)}
$$
![]()
この式を変形すると下記のような「確率の乗法定理」になります。 $$ P(A \cap B)=P(A) P(B \mid A)\quad⑦ $$
![]()
ベイズの定理とは?
さて、ここからが本題です。AIの学習をしていると、よく話に出てくるのが「ベイズの定理」です。⑦の「確率の乗法定理」を利用して
\(A\)
![]() と
\(B\)
と
\(B\)
![]() を入れ替えてみると
$$
P(A \cap B)=P(A) P(B \mid A)\quad⑦
$$
$$
P(A \cap B)=P(B) P(B \mid A)\quad⑧
$$
を入れ替えてみると
$$
P(A \cap B)=P(A) P(B \mid A)\quad⑦
$$
$$
P(A \cap B)=P(B) P(B \mid A)\quad⑧
$$
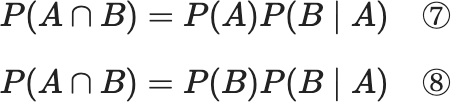
となり、⑦ = ⑧ となるので $$ P(A) P(B \mid A)=P(B) P(A \mid B) $$
![]()
これを変形すると $$ P(A \mid B)=\frac{P(A) P(B \mid A)}{P(B)} \quad ⑨ \text { 【ベイズの定理】 } $$
![]()
ここで
\(P(A)\)
![]() を事前確率、
\(P(A \mid B)\)
を事前確率、
\(P(A \mid B)\)
![]() を事後確率、
\(P(B \mid A)\)
を事後確率、
\(P(B \mid A)\)
![]() を尤度(ゆうど)と呼びます。
尤度とは「あるデータが得られたときに、どんな母数であると、このデータが尤(もっとも)らしいか」という度合いを表すものです。
を尤度(ゆうど)と呼びます。
尤度とは「あるデータが得られたときに、どんな母数であると、このデータが尤(もっとも)らしいか」という度合いを表すものです。
例えば迷惑メールの判定をする場合に、
事象
\(A\)
![]() を「1通のメールを選んだとき、そのメールが迷惑メールである」
を「1通のメールを選んだとき、そのメールが迷惑メールである」
事象
\(B\)
![]() を「1通のメールを選んだとき、そのメールが英文である」とすると、
を「1通のメールを選んだとき、そのメールが英文である」とすると、
ベイズの定理と、それぞれの確率から「迷惑メールが英語である場合」が求まります。
正規分布(ガウス分布)とは?
前出の確率変数と確率分布の例では、確率変数
\(X\)
![]() がサイコロの目のような離散型で説明しました。しかし確率変数
\(X\)
がサイコロの目のような離散型で説明しました。しかし確率変数
\(X\)
![]() が離散型でなく、例えば身長や体重のように連続型の実数値のケースの場合もあります。この連続型の確率分布で表される曲線
\(f(x)\)
が離散型でなく、例えば身長や体重のように連続型の実数値のケースの場合もあります。この連続型の確率分布で表される曲線
\(f(x)\)
![]() を「確率密度関数」と呼びます。
を「確率密度関数」と呼びます。
確率密度関数には、以下のような性質があります(離散型の確率分布の性質と対比すると分かりやすいかもしれません)。
確率の総和は定義で1になるので、密度関数と
\(X\)
![]() 軸で囲まれた図形の面積は1になります。
$$
\int_{-\infty}^{\infty} f(x) d x=1
$$
軸で囲まれた図形の面積は1になります。
$$
\int_{-\infty}^{\infty} f(x) d x=1
$$
![]()
(本稿では積分について説明していませんが、
\(\int\)
![]() は積分記号で、ある区間の面積を求める場合に使います)
は積分記号で、ある区間の面積を求める場合に使います)
次に、任意の
\(a, b(a<b)\)
![]() に対して、
\(X\)
に対して、
\(X\)
![]() が \(a\)
が \(a\)
![]() から
\(b\)
から
\(b\)
![]() までの値を取る確率は、確率密度関数と
\(X=a \quad X=b\)
までの値を取る確率は、確率密度関数と
\(X=a \quad X=b\)
![]() で囲まれた部分の面積になるということです。すなわち
$$
P(a \leq X \leq b)=\int_{a}^{b} f(x) d x
$$
で囲まれた部分の面積になるということです。すなわち
$$
P(a \leq X \leq b)=\int_{a}^{b} f(x) d x
$$
![]()
また確率の定義では、確率が負になることはないため
\(f(x) \geq 0 \quad\)
![]() となります。
となります。
さらに、この曲線
\(f(x)\)
![]() が平均
\(\mu\)
が平均
\(\mu\)
![]() 、標準偏差
\(\sigma\)
、標準偏差
\(\sigma\)
![]() を持ち、
$$
f(x)=\frac{1}{\sqrt{2 \pi \sigma}} {\it exp} \left(\frac{(x-\mu)^{2}}{2 \sigma^{2}}\right)
$$
を持ち、
$$
f(x)=\frac{1}{\sqrt{2 \pi \sigma}} {\it exp} \left(\frac{(x-\mu)^{2}}{2 \sigma^{2}}\right)
$$
![]()
となる曲線で表現されるときの確率分布を「正規分布」といいます。
正規分布は、ガウス分布とも呼ばれていますが、なぜ重要かというと世の中で多くのデータが正規分布に従うことが知られているからです(すべてに当てはまるわけではありません)。一見すると指数関数が出てきたりするので、すごく難しい式のように見えますが、変数は
\(X\)
![]() だけしかありませんので恐れないでください。
だけしかありませんので恐れないでください。
ここで重要な点は、平均
\(\mu\)
![]() と標準偏差
\(\sigma\)
と標準偏差
\(\sigma\)
![]() に対して、何%がその分布に入っているかということです。よく「3シグマ」という言葉を使いますが、例えば、下図のように人の身長や体重などで統計を取ると、
\(\mu \pm 3 \sigma\)
に対して、何%がその分布に入っているかということです。よく「3シグマ」という言葉を使いますが、例えば、下図のように人の身長や体重などで統計を取ると、
\(\mu \pm 3 \sigma\)
![]() の範囲内に全体のデータの99.7%が入ります。この性質を利用して、
\(2 \sigma\)
の範囲内に全体のデータの99.7%が入ります。この性質を利用して、
\(2 \sigma\)
![]() や
\(3 \sigma\)
や
\(3 \sigma\)
![]() 以上外れたデータを「外れ値」として判断するケースがあります。IoTセンサなどでデータを収集し、何か突出した異常なデータを外れ値として検出したり、機械学習の前処理として、利用できないようなデータをクレンジング(きれいにする)する際に利用したりします。
以上外れたデータを「外れ値」として判断するケースがあります。IoTセンサなどでデータを収集し、何か突出した異常なデータを外れ値として検出したり、機械学習の前処理として、利用できないようなデータをクレンジング(きれいにする)する際に利用したりします。

エンジニアとしての市場価値を知るために
年収査定を受ける(無料)まとめ
機械学習における数学で、まず最初に押さえておきたいことは、やはり最小二乗法、勾配降下法でしょう。モデル最適化のパラメータを決定するために、誤差の二乗の和が最小になるようにするという発想は、データ解析における基本中の基本です。回帰分析はもちろん、教師あり学習編で触れたSVM(サポートベクターマシン)、さらにはディープラーニングのパラメータなど、さまざまな手法で必要になる標準技法として知られています。
ここでは説明を簡単にするために、多変数関数でも2変数までしか扱いませんでしたが、機械学習では2変数以上で処理するケースがほとんどです。しかし、基本的な処理の考え方を知っていれば、それ以上の多変数に対しても理解が早まるため、まずは基本を押さえておきましょう。
この記事では、機械学習における数学に興味を持ち始めた方に向けて基本情報をお伝えしてきましたが、本稿をお読みの方の中には、より具体的な技術を学んでいる方もいることでしょう。
身につけたスキルを武器に、転職も含めてキャリアに活かしたいとお考えなら、転職エージェントを利用するのも一案です。
dodaエージェントサービスでも、関連の求人市場の動向調査や具体的な案件探し、転職につなげるための面接対策など、転職活動のお手伝いをいたしますのでぜひお気軽にご相談ください。
エンジニアとしての市場価値を知るために
年収査定を受ける(無料)
技術評論社 デジタルコンテンツ編集チーム
理工書やコンピュータ関連書籍を中心に刊行している技術評論社のデジタルコンテンツ編集チームでは、同社のWebメディア「gihyo.jp」をはじめ、クライアント企業のコンテンツ制作などを幅広く手掛ける。
キーワードで記事を絞り込む
- 自分の強みや志向性を理解して、キャリアプランに役立てよう
- キャリアタイプ診断を受ける
- ITエンジニア専任のキャリアアドバイザーに無料で転職相談
- エージェントサービスに申し込む(無料)
- キャリアプランに合う求人を探してみよう
- ITエンジニア求人を探す



 ×
×
 ×
×





