

教師なし学習とは?教師あり学習との違いや概要、手法を解説
AI(Artificial Intelligence:人工知能)を実現する手法で、最近特によく話題に上がるのは「ディープラーニング」(Deep Learning:深層学習)ですが、それ以外にも多くの手法があります。例えば、AIのカギとなる「機械学習」(Machine Learning)は、以前からある重要な技術として知られています。ここでは機械学習を支える「教師なし学習」(Unsupervised Learning)について詳しく解説します。
機械学習の基礎については以下の記事で詳しく解説しているため、あわせてご覧ください。
エンジニアとしての市場価値を知るために
年収査定を受ける(無料)そもそも教師なし学習とは何か?
「教師なし学習」(Unsupervised Learning)とは、与えられたデータの本質的な構造や法則をモデルによって自動的に抽出する手法で、AIという大枠の中にある機械学習の代表的な学習法の一つという位置づけになります。
この節では、教師なし学習を説明する前に、大前提となる機械学習について簡単に触れておきましょう。
機械学習は、与えられた入力データと出力データから、その関係を表すモデル(関係式、関数)をコンピュータが自動で導き出す手法です。ここで入力データは「説明変数」、出力データは「目的変数」とも呼ばれます。
エンジニアとしての市場価値を知るために
年収査定を受ける(無料)教師なし学習とその他の機械学習
機械学習の種類と教師なし学習のゴール
機械学習の一種である教師なし学習では、入力データをそのまま与えて、学習を進められる点が大きな特徴です。もともと正解となるデータがない場合に、データの構造や法則性などの関係をコンピュータが自動で解析して抽出する手法になります。
例えば、従来まったく販売したことのないような新製品のターゲット市場を決める場合など、結果にコミットするデータがないような場合に利用されます。
機械学習には「教師なし学習」のほかにも、「教師あり学習」(Supervised Learning)や「強化学習」(Reinforcement Learning)といった手法もあります。これらの中で、教師なし学習の利用頻度は、教師あり学習よりもまだ低いのですが、教師あり学習を実施する前段階にも適用できたり、ビッグデータの解析に用いられたりするため、非常に重要な手法となります。
人間は、特に何か意識しなくても多くのモノを見て区別することができます。例えば、名前の分からない複数種の野菜が陳列されていたとき、その形やサイズや色などを見て特徴を捉え、どのようにまとめればよいかを直感的に判断できます。教師なし学習では、そのような能力をモデルによって再現し、未知のデータをまとめていくことが最終的なゴールとなります。
一方、教師あり学習は、あらかじめ正解となる答えをラベリングし、ペアのデータセットを大量に用意し、そこから関係性を表すモデルを作るため、教師なし学習よりも手間とコストがかかります。しかし、新しい未知のデータを入力すると、正解となる結果を高精度に予測できるようになります。また強化学習は、出力される結果に対して報酬、すなわち点数(スコア)をつけて、その報酬が最大になるように学習させ、最適な結果を導き出せます。
教師あり学習、強化学習については以下の記事でも詳しく解説しているため、あわせてご覧ください。
エンジニアとしての市場価値を知るために
年収査定を受ける(無料)教師なし学習が扱う2つの手法
「クラスター分析」と「次元削減」
教師なし学習が扱う代表的な問題には「クラスター分析(クラスタリング)」(cluster analysis) と「次元削減」(dimension reduction)があります。
クラスター分析のclusterとは、英語で「房」や「塊」といった意味があり、特徴が似ているものが集まった状態を指します。つまりクラスター分析は、大量のデータから類似するものを(特徴量の近いもの)、いくつかの集団にまとめるための分析手法になります。この手法で特徴が近いデータの集団をつくることを「クラスタリング」といいます。
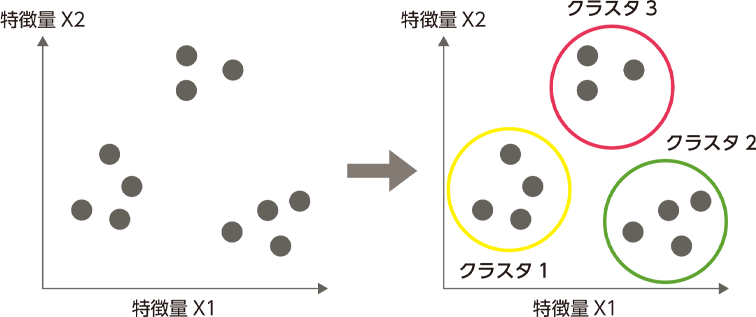
なお、クラスターは、教師あり学習のクラス分類と似ているので注意しましょう。クラス分類では、人間が教師となって正解データ(目的変数)をラベリングし、訓練データをセットで適用します。
そこから最適な関係性を導き出すモデルを作り、未知のデータに対して正しい回答を与えますが、クラスタリングの場合は正解データがない状態での分類です。分類はできますが、それぞれの集団の持つ意味は明確ではありません。その結果は人間が解釈する必要があります。
クラスタリングとクラス分類の違いの分かりやすいケースとして、例えばテストの結果を「50点以上」「50点未満」というように、あらかじめ2グループに分ける場合ではクラス分類になります。しかし「数学が得意」とか、「国語が得意」というように、似たような特徴を持つグループに自動的に分ける手法はクラスタリングになります(そのままでは何の集団か分からないので、数学が得意といったグループの意味付けは、人間が行うことになります)。
クラスター分析は、ビッグデータのような膨大なデータやグループから機械的に「似たもの同士」を集めてくれます。大量のデータでも扱いやすく、人間では分からない潜在的なクラスターや異常なデータなどの発見に役立ちます。ビジネス領域では、顧客を分析するマーケティングなどによく利用されています。
エンジニアとしての市場価値を知るために
年収査定を受ける(無料)クラスター分析をタイプ別に紹介
階層的クラスタリングと非階層的クラスタリング
クラスター分析の種類には、分類対象が少ない場合に用いられる「階層的クラスタリング」と、分類対象が多数ある場合に適用される「非階層的クラスタリング」があります。
階層的クラスタリングは、似ている特徴のあるデータをクラスター順に階層的に1つずつまとめていき、最終的に1つの大きなクラスターになるまで繰り返していきます。その経過はトーナメント表(樹形図)のような図で視覚化されるため、データの特徴を把握しやすい分析法です。
また、非階層的クラスタリングのほうは、階層的な構造を持ちません。前もって、いくつかのクラスターに分ければよいのかを設定し、そのクラスター数に応じてデータを分割していく手法です(ただし数を決めないで機械が自動分割してくれる手法もあります)。計算量が少なく済むため、ビッグデータなど処理件数が膨大な場合に特に有効で重宝されています。
クラスタリングを行うための仕組み
ここからは教師なし学習の代表的手法であるクラスタリングについて、さらに深掘りしていきましょう。
階層的クラスタリングでは、すべてのデータ間で互いの類似度や非類似度を計算し、似たもの同士を同じクラスターにまとめて、階層型クラスターを形成します。このとき互いのデータの距離を計算し、その距離が近いかどうかによって類似度を判断します。
最初は三平方の定理で「ユークリッド距離」を求めますが、その後の結合工程の距離測定には、いろいろな方法が使われます。よく利用されるのは分散(ばらつき具合)が最小になるようにデータを結合する「ウォード法」です。
また、非階層的クラスタリングに利用される代表的な実行法としては「k-means法」(k-平均法)があります。あらかじめ指定された数(たとえばk個)のデータをランダムに「プロトタイプ」として指定します。そしてプロトタイプ以外の個体データを、最も近いプロトタイプに割り当てることで、最初のクラスターを作ります。
次に、その時点でのクラスターに所属するデータから、クラスターごとに重心(平均)を求めます。この重心が決まったら、さらに最も距離の近い重心のクラスターの各データを割り当て直します。このように何度もクラスターの重心の計算を行っていくと、最終的に重心が動かなくなって収束し、近いデータ同士がk個のクラスターに集まるようになるわけです。

エンジニアとしての市場価値を知るために
年収査定を受ける(無料)次元削減とは、どんな手法なのか?
もう1つ教師なし学習で扱う代表的なものが「次元削減」です。こちらは多数のデータから重要な情報を抜き出し、それほど重要でない情報を削減することで、データを要約して次元数を減らす手法です。
次元を削減するメリットとは?
次元削減は、簡単にいうとデータを要約することです。なぜ、このようなことをするのかというと、次元を削減すると人間にとって理解しやすくなるからです。例えば、人間は3次元の世界は感覚でも分かりますが、4次元以上の世界になると頭ではイメージできません。そこで多次元データを3次元以下のデータに落としてデータを視覚化することで、重要な情報(特徴量)を際立たせることができるわけです。

例えば上図のように2次元のデータを直線の1次元上に落とし込む
このとき次元を削減しても、データは特徴を保っていることが分かる
また機械学習を行う際にも次元が大きすぎると、逆に特徴や類似性が分かりづらくなるという「次元の呪い」が起きてしまいます。そこで、この問題を回避するためにも次元を減らして見通しをよくする必要があるのです。さらに、大きな高次元から低次元に置き換えることで、データ量も圧縮できます。膨大なデータに対して次元削減を適用すると、計算量を大幅に減らせて、処理時間も短くなります。
主成分分析によって次元を減らすには?
具体的に次元を削減するためには「主成分分析」(PCA:Principal Component Analysis)がよく使われます。主成分分析は「観測変数」(多数の変数の情報)を、できるだけ少ない「合成変数」(指標や次元)で要約する手法です。ここで観測変数を要約した合成変数のことを「主成分」といいます。
一般的には、主成分分析では1~3つの主成分に置き換えます。前述のように人間は3次元以下ならば、次元のイメージを捉えられるからです。主成分は最初に求められるものから順に、第1主成分、第2主成分、第3主成分……と呼びます。中でも第1主成分は、分析に使用した対象の「総合力」を示しています。というのも、第1主成分が分析に使用した合成変数の中で、最も多く元のデータの情報を反映しているからです。
主成分分析は、少し難しい表現をすると「データを射影(変換)し、別の視点から捉えてデータを扱いやすくする操作」のことです。ここで、例えば2次元(平面)のデータを1次元(直線)に落とし込む場合に、射影する軸の選び方が重要になります。
軸上に変換される前のデータの重要な特徴を残すためには、変換後にも情報ができるだけそぎ落とされずに多く含まれるようにすることが大切です(情報損失量を少なくするといいます)。そのためには、データの散らばり具合(分散)が最大になるようにする必要があります。
主成分分析を行うことで、データの持つ情報をできるかぎり損なわずに全体の雰囲気を可視化し、理解しやすくすることができます。ビジネス面では、ビッグデータの分析、店舗分析、成績の総合評価などに利用されています。
エンジニアとしての市場価値を知るために
年収査定を受ける(無料)まとめ
このように機械学習を支える教師なし学習は、AIを実現するうえで非常に重要な手法です。ビジネスにおいてビッグデータなど、大量のデータを分析する際に大いに役立ちます。未知のデータから潜在的な法則や本質的な構造を発見し、有益な知見を得ることが可能になります。
この記事では、機械学習に興味を持ち始めた方に向けて、教師なし学習の基礎をお伝えしてきましたが、本記事をお読みの方の中には、より具体的な技術を学んでいる方もいることでしょう。
もし、機械学習に関する技術を学び、転職も含めてキャリアに活かしたいとお考えなら、転職エージェントサービスを利用するのも一案です。
dodaエージェントサービスでも、機械学習に関する求人の市場感や具体的な求人探し、転職につなげるための独学ポイントや面接対策など、転職活動のお手伝いをいたしますので、ぜひお気軽にご相談ください。
エンジニアとしての市場価値を知るために
年収査定を受ける(無料)
技術評論社 デジタルコンテンツ編集チーム
理工書やコンピュータ関連書籍を中心に刊行している技術評論社のデジタルコンテンツ編集チームでは、同社のWebメディア「gihyo.jp」をはじめ、クライアント企業のコンテンツ制作などを幅広く手掛ける。
キーワードで記事を絞り込む
- 自分の強みや志向性を理解して、キャリアプランに役立てよう
- キャリアタイプ診断を受ける
- ITエンジニア専任のキャリアアドバイザーに無料で転職相談
- エージェントサービスに申し込む(無料)
- キャリアプランに合う求人を探してみよう
- ITエンジニア求人を探す



 ×
×
 ×
×





