

ディープラーニング(深層学習)とは?基礎知識や機械学習との違いを解説
ディープラーニング(Deep Learning)は、深層学習とも呼ばれる機械学習(Machine Learning)の手法のひとつです。自動翻訳や画像生成、チャットボットなどで目覚ましい進化を遂げており、近年のAI(Artificial Intelligence:人工知能)というと、ほぼディープラーニングを使ったものといえるくらい社会にも浸透している技術です。ここでは、ディープラーニングについて改めてどんなものか、どのような特徴や課題があるのかを整理してみます。
機械学習の基礎については以下の記事で詳しく解説しているため、あわせてご覧ください。
エンジニアとしての市場価値を知るために
年収査定を受ける(無料)ディープラーニングと教師あり学習・教師なし学習・強化学習との違い
機械学習には「教師あり学習(Supervised Learning)」「教師なし学習(Unsupervised Learning)」「強化学習(Reinforcement Learning)」の3つの分類があるといった解説を目にすることもあるでしょう。これらの用語は、主にAIがどうやって学習するのか、その方法に着目した分類といえます。
教師あり学習は、正解となるデータを用意しておき、AIの出力を正解に近づくように調整します。画像認識などに応用されます。教師なし学習の場合、正解データを用意せず、入力データを分析処理することで特定のパターンを抽出し、対応する値を出力させます。必要なパターンを抽出できるように分析処理の方法を調整します。株価予想、テキストマイニングなどのビッグデータ解析が得意とされます。
強化学習は正解データの学習を自動化する手法です。出力に対して一定の評価(報酬)を与え、評価が高くなる手順を覚えさせることができます。ゲームエージェントや自動運転・ロボット制御などに利用されます。
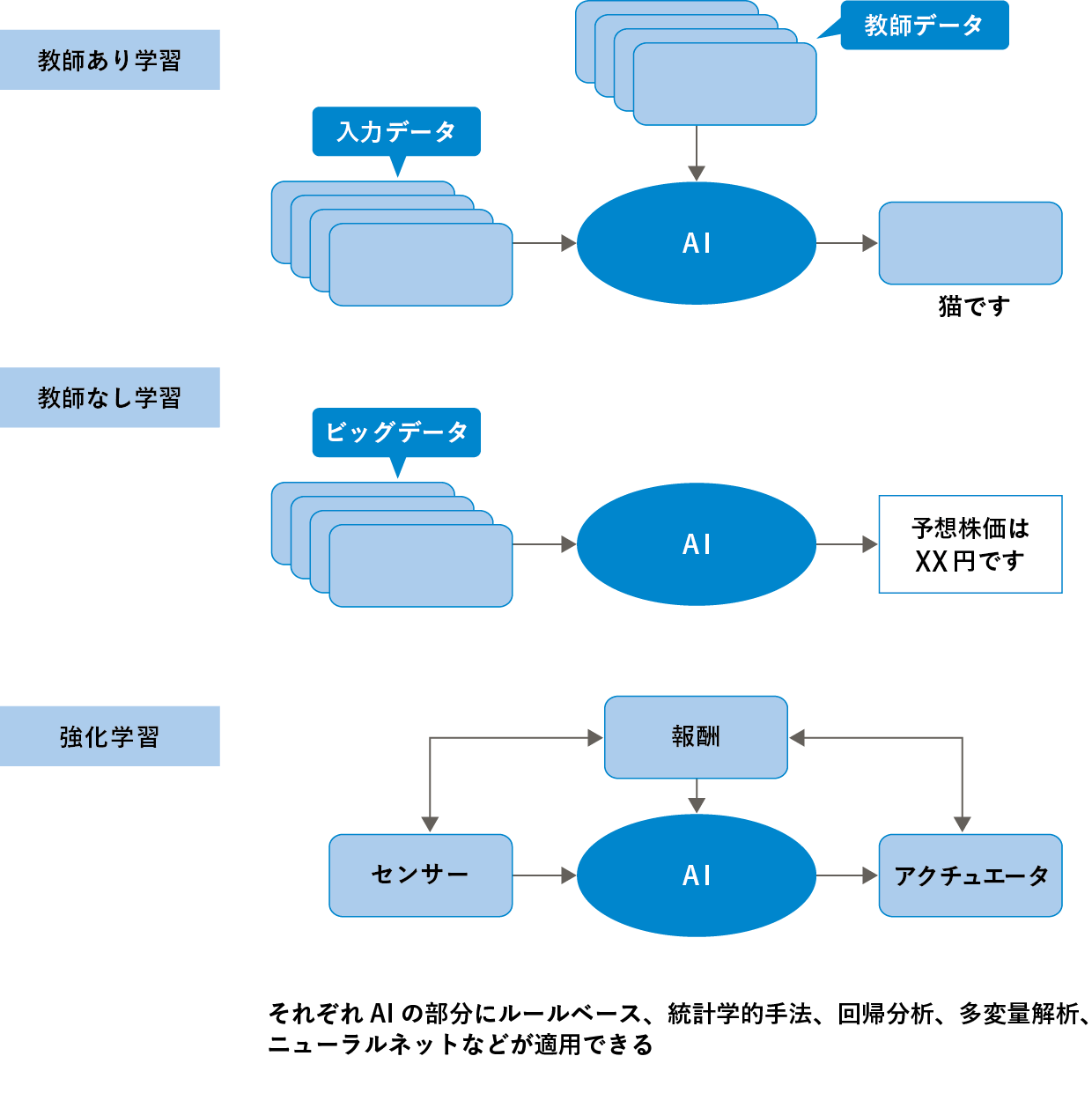
※教師あり学習、教師なし学習、強化学習についての詳しい解説は以下の記事をご覧ください。
改めてディープラーニングとは
ディープラーニングは、これらの機械学習の学習を実現する(実装する)技術を表した言葉です。具体的には、学習によって構築されるAIモデルにニューラルネットワーク(NN)を利用したものをディープラーニング(DL)といいます。
前述の3つの機械学習手法は、入力に対してなんらかの計算処理、評価を行って値を出力しなければなりません。計算処理には、ルールベースの判定、統計分析や多次元行列処理などさまざまなものがありますが、より複雑な計算のためにニューラルネットワークを使う方法があります。ディープラーニングは、ニューラルネットワークを使った機械学習ということができます。
エンジニアとしての市場価値を知るために
年収査定を受ける(無料)DNN(ディープニューラルネットワーク)
ニューラルネットワークは、脳の神経細胞を模した数理モデルです。ネットワークを構成する数理ノードひとつひとつは特定の変換を行う関数のようなものです。このノードを脳の神経細胞のように相互接続させたものがニューラルネットワークです。入力データに対して、各ノードがそれぞれの値を出力して次のノードに渡します。ノードの変換には線形なもの、非線形なものがあります。これらが、階層的につながることで複雑な数理処理を実現します。
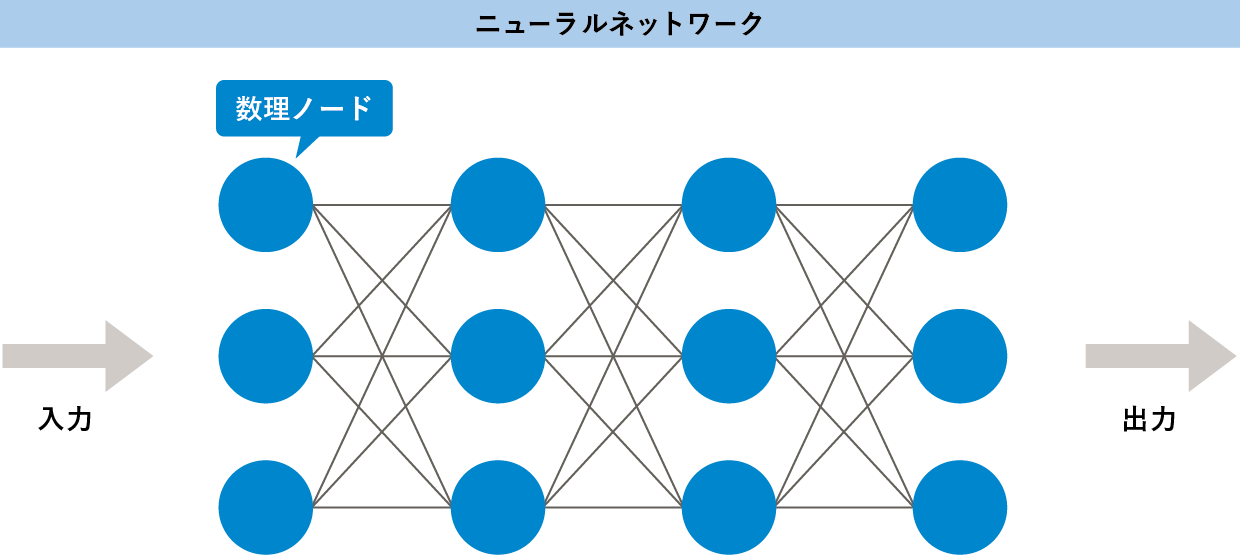
ニューラルネットワークの各ノードの計算方法、つながり方の組み合わせは無数になります。組み合わせを調整して、ある入力パターンに対して特定の値やパターンを出力できれば、機械学習のモデルに応用が可能です。例えば、写真のデータ(ビットマップ)を処理させ、猫が写っている(可能性が高い)ものだけ特定の値を出力できるようにすれば、画像認識のAIを作ることができます。
ニューラルネットワークの数理モデルは、データの分類、回帰分析などさまざまな処理に適用可能です。
じつは、ニューラルネットワークは1960年前後には研究が始まっています。機械学習以外にも、機械の制御や数値解析、並列計算にも以前から使われている技術です。当時のニューラルネットは、並列にならぶノードの階層は3層が一般的でした。入力層と出力層、してその間の隠れ層です。
しかし、2006年にカーネギー・メロン大学のジェフリー・ヒントン教授が4層以上のニューラルネットを用いた図形認識や単語予測で大きな成果を上げました。ヒントン教授のニューラルネットワークは「ディープニューラルネットワーク(DNN)」と名付けられました。
エンジニアとしての市場価値を知るために
年収査定を受ける(無料)ディープラーニングの得意分野
ディープラーニングはDNNを使ったAIモデルを実現する手法の一種です。教師あり学習、教師なし学習(あわせて表現学習ということもあります)、強化学習にも適用することが可能です。
モデル化の範囲が限定されがちなルールベース、確率論や回帰分析などを利用した手法、複雑な関数処理によるAIモデルより、DNNのほうが高い学習効果と出力精度が期待できるとして、さまざまな研究と関連ツール開発が進んでいます。
適用分野は、画像認識や自動翻訳、画像生成、自動運転、チャットボットなどが得意とされています。
自動運転
強化学習はエージェントに特定の動作や処理を学ばせるタスクに向いています。チェスや囲碁のAIエージェントが代表的な応用例ですが、オンラインゲームの世界では、敵キャラクターの動きに強化学習を使っています。ゲームのキャラクターの動きは、そのままロボットの制御や自動車の制御に置き換えることもできます。
現在、無人タクシー、ロボットタクシーの研究が各所で進められています。GoogleやAmazonのように最初からロボットカーによる移動サービスを前提とした自動車もあれば、NVIDIAやトヨタ自動車、TIER IVなどが研究開発を続けている無人タクシーもあります。
これらの制御に、DNNを使った強化学習、深層強化学習を使っている例が増えています。2022年には、AI将棋を開発したエンジニアが起業したTURINGというベンチャー企業が自動運転車両で北海道一周を達成しました。この車両にも深層強化学習が利用されています。
自動運転AIには2つの開発アプローチがあります。ひとつはAIに運転操作の判断までやらせる方法。もうひとつは、画像処理や状況判断をAIに任せてハンドルやアクセル・ブレーキの操作は従来型のプログラムで行うアプローチです。
もちろん、実際には両者を組み合わせて使うこともしばしばです。一般的な自動車に搭載されている自動ブレーキや高速道路等でのハンズオフ走行は、主にカメラやLiDARという3Dレーザースキャナの画像データの認識にAIを使い、車両の制御は従来型プログラムで処理していることが多いです。
テスラやTIER IV、TURINGなどは、車両の走行制御、つまり運転操作までAIに任せるアプローチをとっています。
画像生成・チャットボット
機械学習はディープラーニングによって飛躍的な進化を成し遂げ、今のAIブームの原動力にもなっています。エックス線写真やCT画像からがんを見つける、画像の中の人間を識別する、囲碁やゲームを攻略する、といった単一タスクはすでに人間の能力を超えたといってもいいくらいです。
現在は、画像認識、音声認識、自然言語処理、翻訳などの個別の処理を組み合わせて、より高度なタスクを実現する研究が進んでいます。例えば、画像認識で人間や猫を識別する処理では、画像のノイズを除去したり対象エリアを特定したりするような前処理、特徴点を抽出する処理、それを判別する処理などが必要です。従来であれば、特徴点抽出だけに機械学習を使い、前処理や判定は人間やプログラムが行っていました。
このような処理の方法をEnd-to-end学習といいますが、ディープラーニングの応用として研究開発が進んでいます。テキストから画像を生成するAIやChatGPTは、End-to-end学習の成果といえます。
複雑な質問に人間のように答えてくれるChatGPTや「19世紀のロンドンの街並み」という文章だけで絵画を生成(合成や既存絵画の抽出ではない)してくれるAIは、GAN(敵対的生成ネットワーク)というディープラーニングの手法によって実現されています。GANは、本物を生成するNNと偽物を生成するNNを利用して判定や識別の精度を上げる手法ですが、これを文章や画像の新規生成に応用したものです。
エンジニアとしての市場価値を知るために
年収査定を受ける(無料)ディープラーニングの難しさ
ディープラーニングは現在のところ非常に効果を上げている機械学習の手法です。しかしながら課題もあります。以下に示す課題は、必ずしもディープラーニング特有のものではありませんが、ディープラーニングの適用が広がるAIの課題として認識しておくべきものです。
コスト
深層強化学習では、学習作業を自動化することができます。End-to-end学習の広がりは高度なタスクへのAI活用の道を開きました。しかし、精度の高いAIモデルを作るためには大量のデータを処理させる必要があります。学習はある程度自動化できますが、大量のデータは依然として必要です。
自動運転であれば、AIに走行させた距離で精度や実用性が決まります。走行はシミュレーターを利用することもできますが、シミュレーションのための膨大なデータが必要なのは変わりません。このようなデータを用意するにはコストがかかります。AIに実環境で学習させる場合でも、そのための時間が必要です。データの量と質を高めるにはコストと時間がどうしても必要になります。
なお学習は、すればするほどよいというわけではありません。AIモデルの作り方や用意する学習データによっては、それ以上学習させても精度が上がらないポイントが出てくることがあります。上がらないどころか、精度が極端に下がる場合(破壊的忘却)もあり、ディープラーニングの課題のひとつといわれています。
データの偏り
大量データの課題は、2つの偏りを生みます。ひとつは、モデルとデータの分離です。
AI開発では、アーキテクチャや機械学習のモデル研究も重要ですが、近年はそれ以上にデータを持っていることの重要性が高まっています。ベンチャー企業や優秀なエンジニアは、モデル研究の知識やアイデアは持っていますが、実データを持っていません。
もうひとつの偏りは、学習結果の偏りです。教師あり学習の場合が顕著ですが、最初に正解を決めるのは人間です。強化学習でなにを報酬とするかも人間が調整します。研究者や開発者に明確な意図がなくても、人間が設定した正解や用意したデータに偏りが出ることがあります。
現代のAI研究は、データの量と質が問われています。
エンジニアとしての市場価値を知るために
年収査定を受ける(無料)まとめ
この記事では、深層学習に興味を持ち始めた方に向けて、深層学習の基礎をお伝えしてきましたが、本記事をお読みの方の中には、より具体的な技術を学んでいる方もいることでしょう。
もし、深層学習に関する技術を学び、転職も含めてキャリアに活かしたいとお考えなら、転職エージェントを利用するのも一案です。
dodaエージェントサービスでも、深層学習に関する求人の市場感や具体的な求人探し、転職につなげるための面接対策など、転職活動のお手伝いをいたしますので、ぜひお気軽にご相談ください。
エンジニアとしての市場価値を知るために
年収査定を受ける(無料)
技術評論社 デジタルコンテンツ編集チーム
理工書やコンピュータ関連書籍を中心に刊行している技術評論社のデジタルコンテンツ編集チームでは、同社のWebメディア「gihyo.jp」をはじめ、クライアント企業のコンテンツ制作などを幅広く手掛ける。
キーワードで記事を絞り込む
- 自分の強みや志向性を理解して、キャリアプランに役立てよう
- キャリアタイプ診断を受ける
- ITエンジニア専任のキャリアアドバイザーに無料で転職相談
- エージェントサービスに申し込む(無料)
- キャリアプランに合う求人を探してみよう
- ITエンジニア求人を探す



 ×
×
 ×
×





